AI 推理芯片光谱 — 通用 GPU 到模型刻片的七档专用化
如果只用一句话概括 2025-2026 年 AI 推理芯片的格局,它是一条光谱:从 NVIDIA GPU 的「什么都能跑」到 Taalas HC1 的「只能跑一个模型」,中间精确地排着七档梯度。每往右一档,速度涨 3-10×,但能跑的模型种类切掉一块。
这不是 NVIDIA 一家通吃的故事。AI 推理在 2026 年占到全部 AI 工作负载的约三分之二,体量大到能养活一批专用芯片公司;大模型架构在 2022 年后意外地收敛到 Transformer,让「为某一种神经网络专门设计电路」第一次有了商业意义;同时数据中心的电力瓶颈让能效比绝对算力更值钱 — 这三件事同时发生,才把过去二十年只在学术论文里出现的非通用架构推到了商业舞台中央。
这篇文章不按厂商分类,按架构原理分类。我们会沿着光谱从左往右走,看每一档分别用什么物理机制把「专用化」往前推一步、又付出了什么代价。最后再单独讨论光子路线 — 它不在主光谱上,但在「光计算 vs 光互联」这条平行分支上有着完全不同的命运。
概览 — 一条光谱压缩七条路线
一张光谱图 — GPU 到 Taalas 的七档梯度
把七档梯度并排放在一根轴上,你会看到一个很整齐的渐变 — 颜色从冷色(通用)到暖色(专用)线性过渡,速度从左侧的几十 tok/s 一路冲到右侧的几万 tok/s。
这条光谱的一个微妙之处:Cerebras 不在「专用化光谱」上,它是「另一种物理实现」的通用并行 — 用一整片晶圆解决片间通信瓶颈,而不是改电路拓扑。但因为它跟 NVIDIA GPU 在「通用度」这一维上几乎并列,所以我把它放在最左侧靠近 GPU 的位置。后面会专门解释这个区分。
为什么是 2025-2026 — 四个条件同时成立
这条光谱不是 2026 年才有的。脉动阵列 1979 年就有了论文,存内计算从 2010 年代起一直在学术界打转,光子计算可以追溯到 1980 年代的光学神经网络。新的不是技术,是它们突然同时变得商业可行。背后是四个条件同时成立:
- 大模型架构在 2022 年之后意外地收敛到 Transformer。CNN/RNN/Transformer 在 2018 年还在三足鼎立,谁也不敢把硅片为某一种网络死写。今天 GPT/Llama/Qwen/DeepSeek 全都是 Transformer 变体 — 这给了「专用 ASIC」第一次有意义的 5-10 年硬件生命周期窗口。
- AI 推理的规模大到能养活专用硬件。Deloitte 预计 2026 年推理占全部 AI 工作负载约三分之二,McKinsey 预测 2027 年到 80%。这个数字大到值得为一个特定模型流片 — 哪怕只服役一年,部署量也能摊薄成本。
- 推理的精度容忍度突破临界点。NVIDIA 自己把主推精度从 FP16 一路降到 FP8、FP4。每降一档,同样硅片可以塞 2-4 倍的 MAC。低精度让「模拟物理过程代替计算」(光子、模拟存内计算)第一次进入误差容忍范围。
- 数据中心的瓶颈从「算力」转向「电力」。单颗 GPU 一年的电费已经接近芯片本身的售价;美国部分地区因 AI 数据中心导致电网吃紧。在「算力 ≈ 电力」的时代,能效比绝对算力更值钱 — 这才是非 GPU 路线真正的卖点。
少任何一个条件,这条光谱都不会成立。比如 2018 年的算力市场规模养不起专用 ASIC,2020 年的 FP32 主导让模拟计算精度不够,2014 年的 RNN/Transformer/CNN 共存让没人敢「赌一种架构」。2025-2026 是窗口期 — 这个窗口大概持续 5-7 年,即 Transformer 的主导地位稳定期。
七档梯度对比 — 速度 vs 灵活性
把七档梯度的关键参数放在一张表里 — 这是后面所有讨论的「速查表」:
| 档位 | 代表产品 | 架构核心 | Llama 70B 单流 tok/s | 灵活性 | 状态 |
|---|---|---|---|---|---|
| 1 | NVIDIA H100 / B200 | CUDA + Tensor Core | ~50 | 任意算子 + 训练 + 推理 + HPC | 占据 >80% 训练市场 |
| 2 | Cerebras WSE-3 | 晶圆级集成 | ~2,000 | 任意模型 + 训练 + 推理 | 2026/5 IPO,~490 亿估值 |
| 3 | Google TPU v7 | 脉动阵列 ASIC | ~150 (Trillium) | 主流稠密模型 | 已规模化,Anthropic 100 万 TPU |
| 4 | Groq LPU | 静态数据流 | ~600 | 任意 Transformer | 估值 69 亿,NVIDIA 200 亿背书 |
| 5 | d-Matrix Corsair | 数字存内计算 | ~500 (2ms/tok) | Transformer 家族 | 已出货,估值 20 亿 |
| 6 | Etched Sohu | Transformer ASIC | ~60,000 (8 卡) | 仅 Transformer | 早期客户出货 |
| 7 | Taalas HC1 | 模型刻片 | ~17,000 (Llama 8B 单用户) | 单一模型 | 2026/2 发布,2 个月流片对冲 |
注意第 6、7 档的 tok/s 是不同基准下的数字 — Etched 的 60K 是 8 卡服务器在 Llama 70B 的总吞吐,Taalas 的 17K 是单芯片在 Llama 8B 的单用户吞吐。两者都不能直接拿来横向比 — 越往右专用化程度越高,「公平比较」就越没意义,因为它们能跑的范围已经不同了。
通用并行 — NVIDIA GPU 与 Cerebras 晶圆
光谱最左侧的两档都属于「通用并行」 — 能跑任意算子、训练和推理通吃。但它们的物理实现路线完全不同:NVIDIA 押注「单卡极致 + 高速互联组集群」,Cerebras 押注「整片晶圆消除片间通信」。两条路都没改神经网络计算的本质,只是从不同角度优化「通用并行架构」的物理形态。
NVIDIA GPU — CUDA + Tensor Core 的双轨
NVIDIA 数据中心 GPU 的演化已经在 GPU 架构十年演化 一文里详细拆过 — 这里只点出跟光谱定位相关的两个关键点。

第一,NVIDIA GPU 是双轨架构:CUDA Core 负责通用并行计算(任意指令、任意数据类型),Tensor Core 负责矩阵乘加速。一颗 B200 的 CUDA Core 算力只有 80 TFLOPS,但 Tensor Core 在 FP4 下能跑到 9,000 TFLOPS — 同一颗芯片里有两套完全独立的电路。这意味着 NVIDIA GPU 在「通用 vs 专用」这条光谱上其实是个混合体,Tensor Core 那部分已经很专用了,但因为 CUDA Core 这部分极其通用,整体定位仍然是「最左侧」。
第二,NVIDIA 在推理上的「浪费」是它最大的劣势。一个 Llama 70B 推理任务,主要就是矩阵乘 + softmax + LayerNorm + 激活函数 — CUDA Core 的通用部分基本闲置,RT Core(光线追踪)和视频编解码引擎完全没用上。整颗 GPU 大半的硅片预算其实在「待机」,只有 Tensor Core 在干活。这就是为什么其他六档敢挑战 GPU — 它们都瞄准了「砍掉所有不为推理服务的部分」这一根本浪费。
NVIDIA 自己也意识到了。从 Hopper 开始的 Transformer Engine、Blackwell 的 FP4 数据流、Rubin 的 SM 内 Tensor Core 占比继续上升 — NVIDIA 在悄悄把自己往光谱右侧拖,只是出于生态考虑必须保留 CUDA Core 这条「通用退路」。
Cerebras WSE-3 — 整片晶圆消除片间通信
Cerebras 选了一条很反常识的路 — 别人都是从晶圆上切出小芯片,Cerebras 直接把一整片 300 mm 晶圆当一颗芯片用。
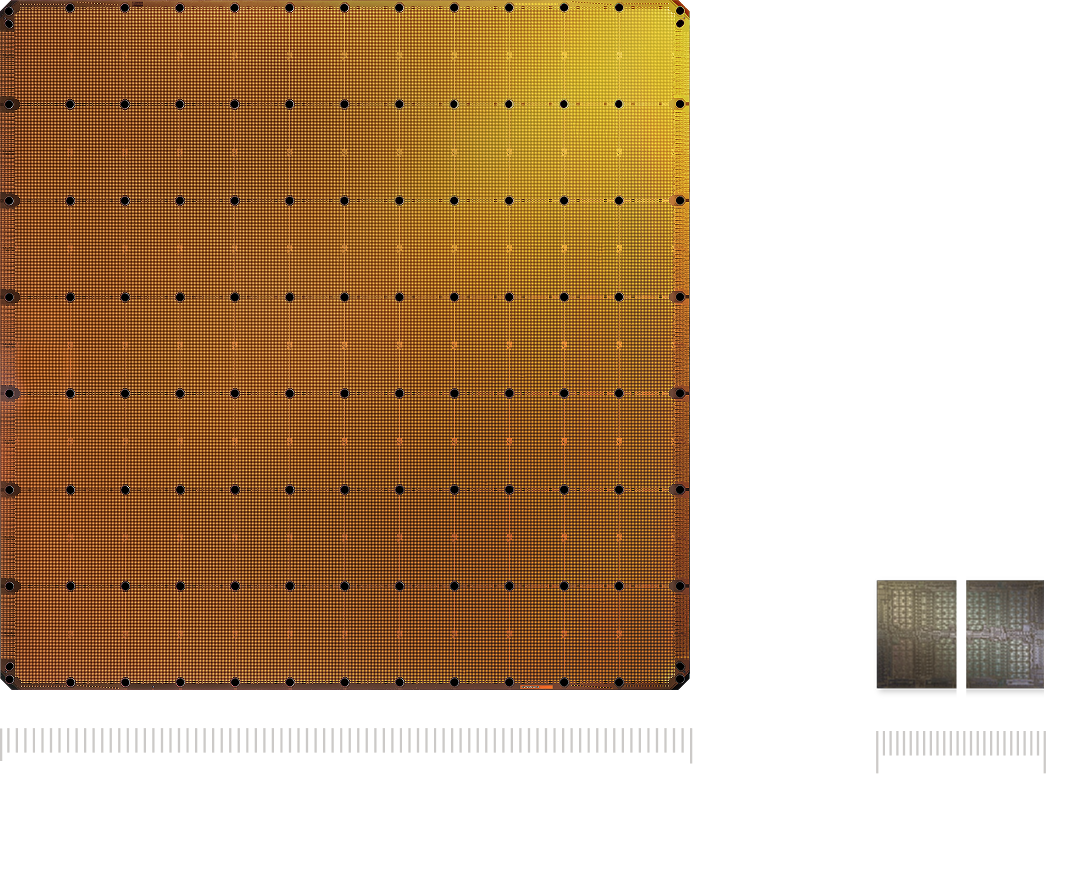
WSE-3 占据整个 300 mm 晶圆,46,225 平方毫米,比 H100 大 57 倍,包含 4 万亿晶体管、90 万核心、44 GB 片上 SRAM、21 PB/秒 的片上内存带宽。它解决了几十年来被认为不可解的工程难题 — 晶圆级良率(用冗余 + 互联重路由)、供电(液冷 + 高密度供电网格)、散热(片上液冷管道)。
但 Cerebras 的关键洞察跟「计算更快」无关,而是 跨芯片通信比片上通信慢 100 倍:
- 传统 GPU 集群:把 Llama 70B 切到 8 颗 H100 上,跨芯片用 NVLink (900 GB/s) 互联 — 仍然比单片 SRAM (~10 TB/s) 慢一个数量级
- Cerebras WSE-3:整个 70B 模型住在一颗「芯片」上 — 完全没有片间通信
这就是为什么 Cerebras 在低延迟推理上能跑出 ~2,000 tok/s 的成绩 — 不是单位算力比 GPU 快,是节省掉了「等数据从隔壁芯片到达」这一大块时间。
但 Cerebras 仍然是「通用并行」 — 芯片内部的计算单元能跑任意 PyTorch 算子,不锁定 Transformer。OpenAI 2026 年初签下的超过 100 亿美元、750 兆瓦合同就是看中这一点 — 不想被某种特定架构绑死,但又要极低延迟。这是 Cerebras 跟后面那些 Transformer 专用芯片最大的差异。
为什么把 Cerebras 放在「通用」一侧 — 工艺创新 vs 架构专用
容易踩的坑是把 Cerebras 归类成「专用 ASIC」 — 因为它「不像传统芯片」。但 Cerebras 的创新维度完全不在「专用化」这条轴上:
| 维度 | NVIDIA GPU | Cerebras WSE-3 | TPU / Groq / d-Matrix… |
|---|---|---|---|
| 架构创新点 | 通用并行 + 异构加速器 | 晶圆级集成(物理形态) | 砍掉通用部分,专做矩阵乘 |
| 能跑什么 | 任意算子 | 任意算子 | 矩阵乘 + 主流神经网络算子 |
| 解决的问题 | 算力提升 | 片间通信瓶颈 | 通用硬件能效浪费 |
Cerebras 的物理形态创新跟「专用化」是正交的两条轴 — 你完全可以做一颗「晶圆级 + 存内计算」的芯片,既消除片间通信,又消除片内 SRAM 到计算单元的搬运。只是工程上太难,目前没人能同时做两个激进的事。Cerebras 选了晶圆级这一边、d-Matrix 选了存内计算这一边,各自先把一边吃透。
所以光谱最左侧并列的两档不是「优劣比较」,是「不同瓶颈各自有人攻」 — NVIDIA 攻「单卡极致」,Cerebras 攻「片间通信」。
砍掉通用部分的脉动阵列 — Google TPU
从这一档开始,我们进入真正的「专用化」 — TPU 是把 GPU 里的 Tensor Core 单独拎出来放大,砍掉 CUDA Core 等通用计算部分,硅片面积全部留给矩阵乘。
脉动阵列电路 — Tensor Core 的「放大版」

脉动阵列(systolic array)的核心思想是 1979 年 H.T. Kung 提出的:数据像「心跳」一样在固定的处理单元(PE)阵列中流动,每个 PE 同时做一次乘加,结果传给邻居或累加在本地。这样:
- 数据进入阵列后,几乎不需要再访问主内存
- 控制电路只需要管「时钟」,不需要管「调度」,所以电路开销极小
- 同样硅片预算下,能塞下比 GPU 多几倍的乘加单元
但脉动阵列也有它的死穴 — 只适合规则的矩阵乘。一旦运算涉及不规则的内存访问(稀疏注意力、动态形状、复杂的 control flow),脉动阵列就跑得很糟。这就是为什么 TPU 跑 Transformer 推理顺,跑 Mamba 这类状态空间模型就吃力。
第七代 Ironwood 把这种「专用化」推到了 Google 自己都觉得需要分化的程度 — 推出了 TPU 8t(训练专用)+ TPU 8i(推理专用) 两款不同的芯片。TPU 8i 配 288 GB HBM 加 384 MB 片上 SRAM,专门为 MoE 和长上下文模型优化。这意味着连 Google 都承认了「训练和推理需要不同硬件」 — 这件事在 2018 年 TPU v3 时代还是不可想象的。
TPU 8t / 8i 训练推理分化 — 第一次承认两端要不同硬件
为什么分化?因为训练和推理的 workload 形态根本不同:
- 训练:批量大(几百到几千)、追求峰值吞吐、对延迟不敏感、需要反向传播(梯度计算)和优化器状态。每一步要的内存量是参数本身的 4-7 倍。
- 推理:批量小(1-16)、追求低延迟、不需要反向传播、内存只需要装下权重 + KV cache。
用同一颗芯片做两件事就会有严重浪费 — 训练芯片在做推理时,大部分电路闲置;推理芯片在做训练时根本带不动反向传播。TPU 8t / 8i 是 Google 第一次把这两个 workload 物理切开 — 推理芯片极致优化「单流低延迟 + 长上下文 KV cache」,训练芯片极致优化「集群协同 + 大批量吞吐」。
这件事对整个产业有信号意义:专用化已经分化到「同一种算子在不同 workload 下需要不同硬件」的精度。我们后面会看到,Groq、d-Matrix、Etched 都只做推理 — 训练这件事在专用化光谱上根本没出现,因为算法还在演进,你不敢为某个特定训练流程流片。
同路线玩家 — AWS Trainium · 华为昇腾 · Meta MTIA
脉动阵列这条路线上不止 Google,几乎所有云厂商都走了这条路:
- AWS Trainium / Inferentia:分工更明确(Trainium 做训练、Inferentia 做推理),已部署 140 万颗 Trainium。Anthropic 的 Claude 在超过 100 万颗 Trainium2 上运行,承诺 10 年向 AWS 投资超过 1000 亿美元锁定最高 5 GW 容量。
- 华为昇腾:达芬奇架构的 3D Cube 矩阵计算单元本质就是脉动阵列。2026 Q1 推出自研 HBM 的昇腾 950PR;通过「超节点」互联构建 Atlas 950/960 SuperPoD 集群,8192 卡集群算力已超过 NVIDIA NVL576 规划。
- Meta MTIA:跟 Broadcom 合作开发的内部 ASIC,主要给 Meta 自己的推荐、广告、Llama 训练 用。
- Microsoft Maia:跟 OpenAI 合作的内部 AI 芯片,2025 年初发布第二代。
把这些放一起看会发现一个产业级规律 — 所有「自家有云 + 模型规模够大」的公司都在做脉动阵列 ASIC。原因很简单:绕过 NVIDIA 的高毛利(40-70%),把这部分利润内部消化掉。这条路线的护城河不是技术 — 脉动阵列本身没那么神秘 — 而是 「自家云的内部出货量足以摊薄流片成本」。这是为什么独立的脉动阵列公司很难活,但云厂商做这事都赚钱。
编译期写死调度 — Groq LPU
往光谱右边再走一档,就到了 Groq LPU(Language Processing Unit) — 它在脉动阵列的「砍掉通用部分」基础上,又砍掉了一样东西:运行时调度。
确定性数据流 — 没有动态调度的代价

Groq 创始人 Jonathan Ross 是 Google TPU 的原作者之一。他认为 TPU 还不够极致 — TPU 虽然砍掉了 CUDA Core,但保留了「按指令执行」这套传统 CPU 模型,运行时仍然有 warp 调度、缓存层级、分支处理这些复杂度。Ross 的洞察是:对于神经网络推理,所有这些「动态行为」都是浪费。
Groq LPU 的核心架构叫「静态调度的张量流处理器」(TSP):
- 编译时就把每个 token、每个时钟周期数据流向哪里完全规划好
- 运行时没有调度开销、没有缓存未命中、没有分支预测错误
- 整个流水线像一台精密的纺织机 — 每个时钟所有齿轮位置都是确定的
这种「确定性」带来了三个直接好处:
- 延迟极低:Llama-3 8B 跑到 1,345 tokens/秒,是 GPU 的几倍到十几倍
- 能效极高:省下的不只是计算能耗,还有调度电路的能耗
- 吞吐可预测:不会出现「这一帧突然卡 100ms」这种 GPU 上常见的现象
代价是:编译时间长、模型切换贵。换一个模型相当于重新设计一台纺织机。但 Groq 解决得很巧妙 — 把编译当成一次性投资,然后把编译好的模型作为「服务」对外提供(GroqCloud API),开发者按 token 付费,完全不需要自己跑编译。
全片上 SRAM — 没有 HBM 的设计哲学
Groq LPU 还有一个反常识的设计:完全不用 HBM。
每颗 LPU 自带 230 MB SRAM,没有 HBM 也没有 DRAM。SRAM 容量很小,但带宽是 HBM 的好几倍,而且能耗低一个数量级。问题是 230 MB 一颗芯片装不下大模型 — 一个 Llama 70B 要 140 GB(FP16)。Groq 的解法是 组集群:几百颗 LPU 用专有的高速互联组成一个集群,每颗 LPU 装模型的一小片。
这就回到了 Cerebras 同样在解决的「片间通信」问题 — Groq 的答案是「自研超低延迟互联」,不像 NVLink 那么通用,但足以让几百颗 LPU 像一个整体工作。
不依赖 HBM 是 Groq 的一个隐藏优势。在 2024-2026 年 HBM 紧缺(三星 / SK Hynix / Micron 产能都被 NVIDIA 锁死)的大背景下,不需要 HBM 等于不需要排队。Groq 可以独立扩产,这是它能在 2024-2025 年快速放量的硬件原因之一。
200 万开发者 + 英伟达 200 亿背书 — 最强的商业验证
Groq 的商业进展是这条光谱上最猛的:
- 2025 年营收预计 5 亿美元,2026 年 12 亿,2027 年 19 亿
- GroqCloud 服务超过 200 万开发者,财富 100 强公司 75% 已开通账户
- 2024 年 8 月 D 轮 6.4 亿美元(估值 28 亿),2025 年 9 月又融 7.5 亿(估值 69 亿),并获得沙特 15 亿美元承诺
但最重磅的事件是 2026 年初的 NVIDIA-Groq 交易:NVIDIA 与 Groq 达成约 200 亿美元的协议,授权 Groq 的 AI 推理技术,并把多名 Groq 高管收编进 NVIDIA。这个动作的含义非常清楚 — NVIDIA 自己也想要 Groq 这条路线的能力,但不想竞争,所以选择「收购技术 + 招人」而不是「正面竞争」。
这是整条光谱上 NVIDIA 唯一一次正式认可一条非 GPU 路线的价值。它意味着 Groq 代表的「编译期写死 + 全片上 SRAM」路线,在低延迟推理场景下有 GPU 怎么改都比不上的优势 — 这个判断是 NVIDIA 用 200 亿美元投票的。
存储与计算物理融合 — d-Matrix 数字存内计算
光谱的中间一档是个看起来「反直觉」的设计 — 让存储单元自己做计算,或者让计算单元和存储单元物理融合在一起。这就是 d-Matrix 走的数字存内计算(DIMC)路线。
内存墙问题 — 数据搬运耗能是计算的 10 倍
要理解为什么有人愿意做这件事,先得理解传统芯片的一个根本浪费 — 「内存墙」问题:
一颗 GPU 跑 Llama 70B 推理,每生成一个 token,理论上要把 700 亿个权重参数从 HBM 全部读到计算单元里走一遍。搬运这些数据消耗的能量是乘加运算本身的 10 倍以上。NVIDIA H100 大半的硅片预算都在解决「怎么把权重数据更快地搬到计算单元」 — HBM3、L2 缓存、TMA 异步搬运,层层优化但本质都是「缓解」,不是「根治」。
d-Matrix 的核心反思是:反正每次推理都要读权重,能不能直接在存权重的地方就把计算做了?
把乘加器塞进 SRAM 旁边 — chiplet 网格

d-Matrix 的具体做法是数字存内计算(DIMC) — 不让存储单元自己做计算,而是把计算单元紧贴在存储阵列旁边。两者物理上交错排布在一颗芯粒(chiplet)里,权重永久驻留,不需要反复搬运。
跟「模拟存内计算」(Mythic、EnCharge AI 走的路线)对比 — 模拟方案试图用 ReRAM 等器件的电导值直接表示权重,让电流流过阵列时用欧姆定律 + 基尔霍夫电流定律物理完成矩阵乘。能效理论上可以高一个数量级,但工程难点极大(ADC 太贵、写入精度差、温度漂移、寿命有限)。
d-Matrix 一开始其实也试过模拟方案(2020 年的 Nighthawk 概念芯片),但很快放弃 — 「把 ADC 塞进每条 bitline 太难」。最终选了数字 IMC(DIMC)路线,牺牲一部分模拟方案的极致能效,换取工程可落地 + 精度可控。这是个非常诚实的判断。
工程上,d-Matrix Corsair 的具体设计:
- 基于 6nm 工艺的 Nighthawk + Jayhawk II 芯粒
- 每个 Nighthawk 集成 4 个神经核心 + 一个 RISC-V CPU
- chiplet 封装,符合标准 PCIe Gen5 全长全高卡规格
- 对比 GPU 方案:10 倍性能,3 倍成本下降,3-5 倍能效提升
- 单卡 Llama 70B 跑出 30,000 tokens/秒、每 token 2 毫秒延迟
d-Matrix 的下一代路线图比这更激进 — 与 Alchip 合作打造全球首款 3D 堆叠 DRAM 方案 3DIMC,将首发于 Corsair 的继任者 Raptor 推理加速器上,号称比 HBM4 方案快 10 倍。这是把「存内」思想从 SRAM 推到 DRAM 的进一步演化。
层内并行 + 层间流水 — 同时炸开 · 流水推进
DIMC 跟 GPU 在「计算如何发生」这件事上有一个微妙但关键的区别 — 层内同时炸开,层间流水推进:
这跟 Google TPU 的脉动阵列完全不同:
- 脉动阵列(TPU):算一层要几百个时钟周期 — 数据像「心跳」一样在 PE 之间一步步移动,要等数据流过整个阵列
- DIMC(d-Matrix):算一层只要几个时钟周期 — 输入广播到所有 PE,同时计算,同时输出
脉动阵列的「流」是细粒度的 — 单元和单元之间数据真的在一步步移动。存内计算更粗粒度 — 层和层之间数据在流动,但一层内部是瞬间完成的。层间像传送带,一层接一层;层内像爆破,一瞬间整层完成。
模型大于硬件时的时间复用 — 把模型切段
DIMC 的一个隐含限制:芯片硬件容量决定了能装多大的模型部分。一颗 Corsair 卡的总存储是 2 GB 高性能内存 + 256 GB 容量内存,塞不下整个 Llama 70B 的所有层同时驻留。
实际工程做法是「时间复用」(time multiplexing):
- 把模型切成几「段」
- 第一段写进硬件,跑完;权重换成下一段,继续跑
- 中间结果暂存在容量内存里
这听起来又退化成 GPU 了 — GPU 也是用有限的计算单元算无限层。但关键差别在搬运频率:
- GPU:每个 token 都要重读所有权重(权重在 HBM)
- DIMC:一组层写进去后,可以处理很多个 token 才换下一组层
DIMC 的核心优势不是「完全消灭权重搬运」,而是把搬运频率从「每 token 一次」降到「每 batch 一次」或更少。这是为什么 d-Matrix 能在保留「能跑任意 Transformer」灵活性的前提下,跑出 GPU 几倍到 10 倍的能效优势。
商业进展上,d-Matrix 是这条光谱中游中最成熟的一档:
- 2024 年底首发 Corsair,2025 Q2 全面上市
- 2025 年底完成 2.75 亿美元 C 轮(估值 20 亿,超额认购),投资方包括微软 M12、卡塔尔投资局(QIA)、Temasek
- 与 Arista、博通、Supermicro 联合发布 SquadRack 开放标准参考架构
- 2026 年 4 月收购 GigaIO 数据中心业务,向 rack-scale 方案延伸
Transformer 算子图刻进硅 — Etched Sohu
再往光谱右侧推一档,就到了一个更激进的设计 — 把整张 Transformer 算子图烧成硬连线电路。Etched Sohu 是这条路线的代表。
把整张算子图烧成专用电路 — 砍掉所有非 Transformer 硬件

Etched 的核心反思跟前面所有路线都不同 — 既然 Transformer 已经赢了,为什么要为「未来可能出现的其他架构」预留硬件?
具体做法:
- 把 Transformer 的所有标准算子(matmul、softmax、LayerNorm、RoPE 位置编码、KV cache 管理等)烧成硬连线电路
- 不保留任何对 CNN、RNN、状态空间模型(Mamba/RWKV)等的支持
- 权重仍然通过软件加载(不像 Taalas 把权重也刻进硅) — 所以能跑任意 Transformer 模型
这样的「砍法」非常激进。Etched 通过移除所有非 Transformer 神经网络所需的硬件,把更多 Transformer 专用计算塞进相同硅片 — 同样的 TSMC 4nm 工艺,Sohu 的「有效 Transformer 算力」比 H100 高一个数量级。
8 卡 Llama 70B 跑出 500K tok/s — 20× H100 服务器
Etched 的性能数据非常震撼:
- 一台 8 卡 Sohu 服务器跑 Llama 70B 超过 500,000 tokens/秒
- 一台 H100 服务器跑同一模型大约 23,000 tokens/秒 — Sohu 快 20× 多
- 一台 B200 服务器约 45,000 tokens/秒 — Sohu 仍快 10×
- 据称 一台 8 卡 Sohu 替代 160 颗 H100
这个数字大到让人怀疑可信度,但底层逻辑是站得住脚的:H100 的硅片大约 70-80% 的面积花在「不为 Transformer 服务」(CUDA Core 的通用部分、RT Core、图形相关电路、各种调度逻辑)。Sohu 把这些全部砍掉,纯粹为 Transformer 推理服务的硅片占比从 ~20% 提升到接近 100% — 算力翻 5 倍是合理的,再叠加专用化的能效优势,综合 10-20 倍并不离谱。
风险 — Transformer 一旦被替代芯片归零
Sohu 的风险非常清楚:如果 Transformer 在 5-7 年内被某种根本不同的架构替代,所有 Sohu 芯片瞬间归零。
潜在威胁:
- Mamba / 状态空间模型:在长上下文场景下比 Transformer 更高效,2024-2025 年学术界有大量进展。
- MoE 极致稀疏化:虽然 MoE 还是 Transformer 家族,但有些激进的稀疏专家方案需要硬件支持的动态路由 — Sohu 是否支持取决于具体实现。
- 新一代「注意力替代」机制:Linear Attention、Retentive Network、xLSTM 等都在挑战标准注意力。
但 Etched 自己的判断是 — Transformer 已经赢得太彻底了。GPT/Claude/Gemini/Qwen/DeepSeek/Llama 全是 Transformer 变体,数百亿美元的训练投资全押注在这上面,改架构的「转移成本」高到行业不会主动去推。这是一个高 beta 的押注:对了估值翻倍,错了归零。
商业上,Etched 估值约 8 亿美元,2024 年起向早期客户出货。比 d-Matrix 估值低不是因为技术差,是因为专用化更深 → 风险更大 → 市场给的折价。这是后面我们会看到的一个普遍规律 — 估值精确对应光谱位置。
把权重物理铸进硅 — Taalas HC1
光谱最右侧的一档是个真正「核选项」 — 不只把架构刻死,连模型的权重也物理铸进硅片。这是 Taalas 走的路。
结构化 ASIC 路线 — 改 2 层 mask · 2 个月流片

Taalas(加拿大公司,2026 年 2 月从隐身状态出来,融资 1.69 亿美元)的核心做法:
- 把特定 LLM 的权重 物理编码进芯片的硅结构里 — 类似 CD-ROM、游戏卡带或印刷书一样
- 完全不需要 HBM 或外部权重存储 — 内存和计算逻辑在单芯片上以 DRAM 级密度结合
- 借用 2000 年代「结构化 ASIC」的思路 — 用门阵列和硬化的 IP 模块,只改变互联层来适配特定工作负载
「只改 2 层 mask」是 Taalas 的关键工程突破。一颗芯片通常有 10+ 层 mask,正常流片要全部重做。Taalas 把所有可重用的电路做成「基础平台」,只为特定模型改 2 层互联 mask — 这让流片成本和时间降了约 10 倍,从拿到一个新模型到造出硬件只需要 2 个月。
首款产品 HC1 的具体参数:
- TSMC 6nm 工艺,815 mm²(接近 H100 的尺寸),约 530 亿晶体管
- 没有 HBM 堆栈,没有 3D 堆叠,没有水冷
- 功耗约 250W,服务器里 10 张 HC1 卡共 2.5 kW,可部署在标准风冷机柜
- 核心机制可能涉及模拟计算技术 — 电阻网络权重编码 + 对数域算术,实现单晶体管乘法
单芯片单模型 17,000 tok/s — 28× B200
Taalas 在「单一模型」基准下的性能数字很炸裂:
- HC1 把 Llama 3.1 8B 物理铸进硅片 — 单用户 17,000 tokens/秒
- 对比 NVIDIA B200 在同一模型 ~594 tokens/秒 — 28× 优势
- 对比 Cerebras WSE-3 ~1,981 tokens/秒 — 8× 优势
- 对比 Groq LPU ~600 tokens/秒 — 28× 优势
- 每百万 token 成本 0.75 美分 — 比 GPU 路径低 20 倍
这是整条光谱上单点性能最极致的一档。但代价已经清楚 — 这一颗芯片只能跑 Llama 3.1 8B,跑不了 Llama 3.2,跑不了 Qwen 2.5,更跑不了任何非 8B 的模型。
用「快速流片」对冲模型迭代 — 30 次流片支持 R1-671B
Taalas 的商业模式很特别 — 拿「快速流片」对冲「模型迭代」:
- 客户决定要部署的特定模型(比如 DeepSeek R1-671B)
- Taalas 在 2 个月内为这个模型流片出几十颗芯片
- 假设这个模型服役 1-2 年,部署量足够大,单位经济学(unit economics)就能成立
- 模型换代时,客户要么重新流片(再等 2 个月),要么换芯片
Taalas 自己宣称 30 次流片就能支持 DeepSeek R1-671B 这种大模型(因为 671B 太大,要分散到多颗芯片上,每颗芯片承载一小段权重)。这本质上是一种「反摩尔定律」的产品策略 — 不靠工艺进步赚钱,靠「快速适配模型变化」的工程能力赚钱。
Taalas 路线的最大风险:
- 模型生命周期 vs 流片周期赛跑。如果某个爆款模型 6 个月就过气,Taalas 的 8 周流片周期都跟不上。这要求商业客户做长期模型选择承诺。
- 硬编码方法创造了新的技术债。出货后 AI 部分无法升级,期望软件更新周期的客户会强烈抵触 — 数据中心客户通常预期硬件服役 5-7 年。
- 客户被锁死。Taalas 芯片只能给特定模型用,客户没法跑其他模型,议价能力极弱。
但 Taalas 的存在本身证明了 — 行业愿意在最极端的「专用化」方向投入实物资本。即使大部分客户最终不会选这条路,光是「这个选项存在」就足以反向施压所有更通用的方案 — d-Matrix、Etched 必须证明自己的灵活性溢价值得几倍的速度差距。
光子路线的分裂 — 计算暂缓 · 互联爆发
到这里七档梯度走完了。但有一条平行的路线值得专门讨论 — 光子(photonic)芯片。它不在主光谱上,但跟主光谱有重要交集:光子在「计算」方向被衍射极限卡住,但在「互联」方向已经规模化。
光子计算的物理优势 — 乘加自然实现 · 能效 · 距离独立
光子计算的核心洞察很简单 — 矩阵乘法的本质是「乘」和「加」,而这两个操作光天生就会:
- 乘法:一束光穿过透光率 50% 的介质,光强自动乘以 0.5。如果用马赫-曾德尔干涉仪(MZI)精确控制透光率,就能让光强乘以任意权重值。
- 加法:两束光照在同一个探测器上,探测器测到的总光强 = 两束光的光强之和。光的物理叠加 = 加法。
- 并行:不同波长(颜色)的光可以在同一介质里互不干扰传播。用 16 种颜色的光在同一根光路上跑,等于 16 次独立计算同时完成 — 这是电子完全做不到的。
这听起来非常美好。光子计算的几个真正吸引人的物理优势:
- 能效极致:Q.ANT NPU 跑工作负载 30W,对比 GPU 700-1000W — 同样矩阵乘任务能耗低一个数量级
- 速度极快:光在硅波导中跑约 7.5 万公里/秒,信号建立时间几乎瞬间
- 天然并行:波分复用让一条光路同时跑十几次独立计算
- 几乎不发热:发热集中在两端的电光/光电转换,中间几乎不发热
- 不受电磁干扰:光是电中性的,几束光在同一介质里互不串扰
衍射极限 — 为什么光子永远做不到纳米级密度
但光子计算有一个根本性的物理瓶颈 — 衍射极限:
光子器件的尺寸不能小于光的波长的一半 — 这是物理定律,叫衍射极限。数据中心光通讯主流用 1310nm 或 1550nm 红外光,衍射极限就是 ~700 nm(半微米)。实际工程中考虑制造容差、损耗控制、波长偏移,光子器件实际尺寸要大得多:
| 光子器件 | 典型尺寸 | 对比电子 |
|---|---|---|
| 单个光波导(一根导光线) | 宽 500 nm, 间距 1-2 μm | 单个晶体管 20-30 nm |
| 微环调制器(MRM) | 直径 5-10 μm | - |
| 马赫-曾德尔调制器(MZM) | 长 100 μm 到几 mm | - |
| 单个 MZI 计算单元 | 几十到几百 μm | 单 Tensor Core ~10 μm |
密度差距约 200-500 倍。这导致一个直接的工程现实 — 一颗 H100 大小的硅片(800 mm²),电子能塞下几十个 1024×1024 的矩阵乘法器,光子能塞下的最大矩阵乘法器大约只有 128×128。
更糟的是 — 这个差距是物理定律决定的,工艺进步解决不了。即使把光子工艺从当前的 45nm/90nm 推到 3nm,光子器件的密度也提升不了多少(因为不是受工艺限制,是受光的波长限制)。除非用 X 射线波长(几纳米),但那个能量太高会破坏硅本身。
光子计算 — 仍在协处理器阶段

光子计算目前的真实状态 — 协处理器,不是替代品。Q.ANT 是这条路线最有 demo 价值的代表:
- 已部署 NPU 在慕尼黑 Leibniz 超算中心(LRZ),作为生产 HPC 协处理器使用
- 在真实工作负载下能效比 GPU 低 6 倍
- 已达到 16 比特浮点精度 — 这是 AI 训练和推理的关键门槛
- NPU 2 已可下单,2026 上半年开始向客户发货,作为标准 19 英寸服务器交付
但光子计算的本质短板还是没解决:
- 物理尺寸:同等算力下,光子芯片比 GPU 大 30-100 倍。Lightmatter Envise(光子计算)路线已经因为这个原因被公司自己「降级」 — Lightmatter 现在主推 Passage(光子互联),Envise 变成研究项目
- 精度有限:模拟计算天然有噪声,16 比特已经是巨大突破,但跟 GPU FP32 的可重复性不可比
- 绝对算力小:2025 年 Nature 上的最先进光子处理器跑出 65.5 TOPS(16 比特),只有 H100 (INT8 ~2000 TOPS)的 3%
所以光子计算路线短期(5 年内)的最优定位就是协处理器 — 让 CPU/GPU 干它擅长的事(控制、调度、非线性运算),把矩阵乘外包给光子。这是 Q.ANT 的实际部署模式。
光子互联 — 已规模化的 GPU 集群升级
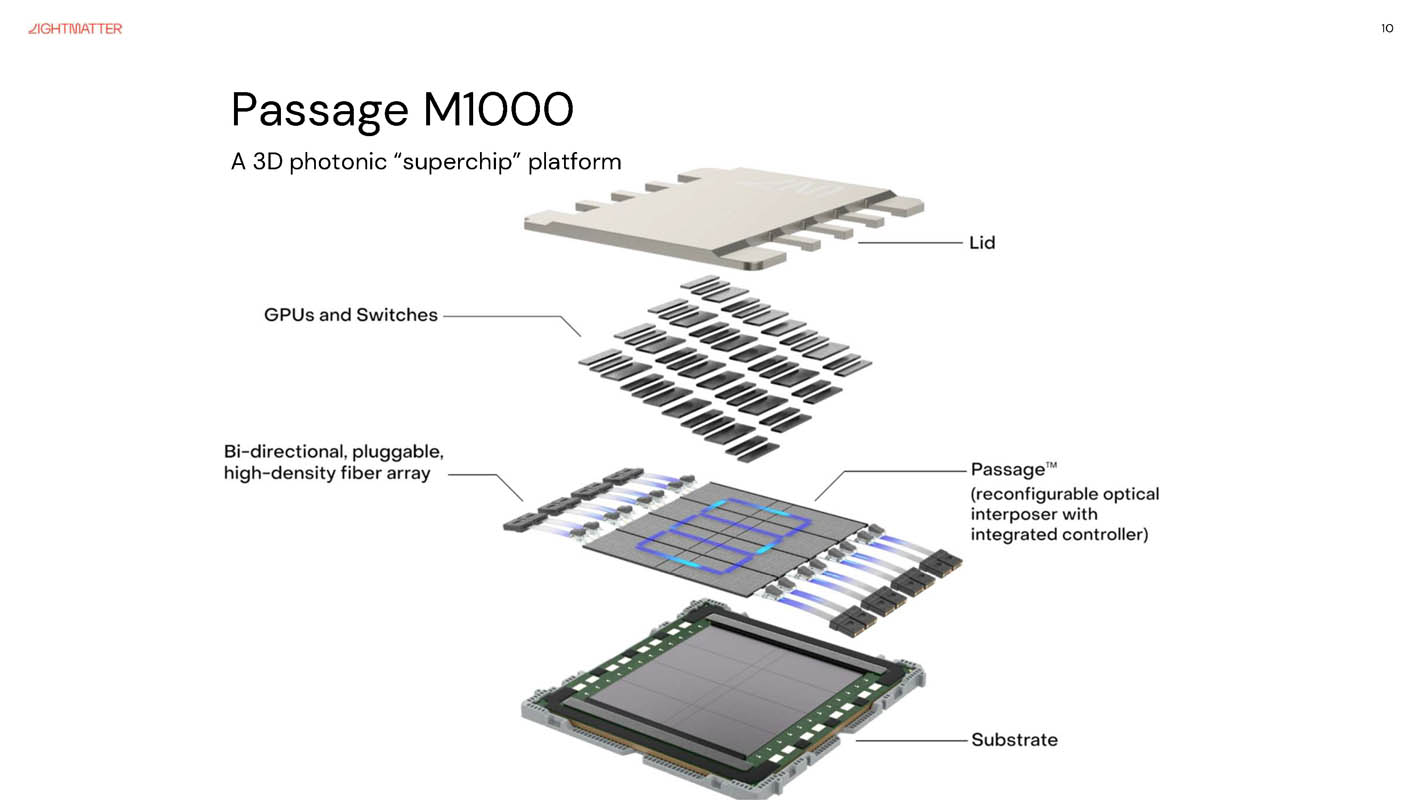
光子的另一条命运完全不同 — 光子互联(photonic interconnect)已经规模化商业应用。它解决的不是计算瓶颈,是 GPU 集群越来越大、电互联带宽撑不住的「互联墙」问题。
光子互联的几个关键优势:
- 带宽密度极高:一根光纤可以用波分复用同时跑几十个不同波长 — 同样物理空间,光的带宽是铜的几十倍
- 距离无关:铜线越长衰减越严重,光纤几乎是距离无关的。AI 数据中心几百米的机柜互联,光是唯一选择
- 能效更优:单 bit 能耗光约 4-5 pJ/bit,铜 SerDes 约 7-15 pJ/bit — 大约 2-3 倍优势
为什么 AI 时代逼出了光子互联?数据非常清楚 — 模型参数 3 年涨了 240 倍,集群规模涨了 10 倍,但电互联带宽只涨了 2 倍。这个缺口越来越大,铜线在 224 Gbps 已经接近物理极限(再快串扰严重)。光是不得不上的。
商业进展极猛:
- Lightmatter:估值 44 亿美元,融资 8.5 亿美元;Passage M1000 已出货,L200 共封装产品 2026 上市
- Ayar Labs:估值超过 10 亿,投资方包括 AMD Ventures、Intel Capital、NVIDIA、3M Ventures
- Celestial AI:2025 年底被 Marvell 32.5 亿美元收购 — 强退出信号
- NVIDIA 自己 2025 年发布 Quantum-X 和 Spectrum-X 光子平台,Quantum-X 交换机 2025 年底开始出货
当 NVIDIA 自己也下场做光子互联时,这条路线就不再是「另类选项」了 — 它是 AI 集群规模化的必经之路。
能耗对比 — 4-5 pJ/bit vs 7-15 pJ/bit
把光子互联和电互联的关键指标放一起:
| 维度 | 电互联(铜 SerDes) | 光互联(硅光 CPO) |
|---|---|---|
| 当前最新单 bit 能耗 | 7-15 pJ/bit | 4-5 pJ/bit |
| 最佳实验室记录 | 1.41 pJ/bit (224 Gb/s, 2022) | 0.7 pJ/bit (112 GBaud, 2023) |
| 带宽天花板 | ~224 Gbps/通道 | 几十波长复用 |
| 距离衰减 | 严重 | 几乎无 |
| 工艺成熟度 | 极成熟 | GF 45nm/90nm 量产 |
| 单 die 集成上限 | 数十 Tbps | >100 Tbps(单封装) |
光子互联的能效优势不是「碾压」(只有 2-3 倍),它的真正优势是带宽密度 + 距离独立性。
综合判断 — 灵活性 vs 效率的取舍光谱
走完七档梯度 + 光子分支,可以把所有数据放在一起做一次综合判断。
七档梯度的速度对比 — Llama 70B / 8B 实测数据
把光谱上所有产品的实测吞吐数据放一起:
| 路线 | 代表产品 | 状态 | Llama 70B (8 卡) | Llama 70B (单流) | 物理实现 |
|---|---|---|---|---|---|
| 通用 GPU | NVIDIA H100 | 已规模化 | ~23,000 tok/s | ~50 tok/s | CUDA + Tensor Core |
| 通用 GPU | NVIDIA H200 | 已规模化 | ~31,712 tok/s | ~70 tok/s | 同上 + HBM3e |
| 通用 GPU | NVIDIA B200 | 已规模化 | ~45,000 tok/s | ~120 tok/s | Blackwell |
| 晶圆级 | Cerebras WSE-3 | 已商用 | - | ~2,000 tok/s | 整片晶圆 |
| 静态数据流 | Groq LPU | 已规模化 | - | ~600 tok/s | 编译期写死 |
| 数字存内 | d-Matrix Corsair | 已出货 | - | ~500 tok/s | 数字存内计算 |
| Transformer ASIC | Etched Sohu | 早期客户 | >500,000 tok/s | ~60,000 tok/s | 算子图刻片 |
| 模型刻片 | Taalas HC1 | 刚发布 | - | 17,000 tok/s (L8B) | 权重铸进硅 |
注意:这些数字来自厂商公开材料和第三方报道,不同测试条件下口径不完全可比 — 但量级关系是清楚的。每往光谱右走一档,速度涨 3-10×,累计跨度接近 1000×。
估值精确对应光谱位置 — 越专用估值越低
把光谱上所有公司的估值排一起,会发现一个很整齐的梯度:
| 公司 | 路线 | 估值 | 估值与最专用的距离 |
|---|---|---|---|
| NVIDIA | GPU(最通用) | 4 万亿+ 美元 | 最左 |
| Cerebras | 晶圆级 | ~490 亿美元(2026/5 IPO 估值) | 已规模化 |
| Groq | 静态数据流 | ~69 亿美元 | NVIDIA 200 亿背书 |
| d-Matrix | 数字存内 | ~20 亿美元(C 轮 2.75 亿) | C 轮超额认购 |
| Etched | Transformer ASIC | ~8 亿美元 | 早期客户出货 |
| Taalas | 模型刻片 | <5 亿美元(估算) | 刚发布,融资 1.69 亿 |
这不是巧合 — 是市场对「专用化风险」的精确定价。越专用的方案,越担心未来模型架构变化导致硬件归零,所以市场给的折价越大。NVIDIA 之所以值 4 万亿,部分原因就是它的「通用性溢价」 — 不管 AI 未来怎么演化,GPU 永远不会归零。
反过来看也合理 — Taalas 估值低不是因为技术差,是因为「赌单一模型」的下行风险天然就大。
未来 3-5 年的稳态格局 — 训练 / 推理 / 互联三块市场
整个 AI 推理芯片格局,未来 3-5 年的稳态大致是这样:
训练市场(70-30 分布) — 这块基本定了:
- NVIDIA(~70%):通用性是训练的核心需求,因为算法还在演进
- Google TPU(~20%):自家云 + Anthropic 等大客户内部消化
- AWS Trainium 等(~10%):云厂商自家场景
推理市场(分裂成几个细分赛道) — 这才是真正多元的地方:
- 大型云推理服务 → GPU + TPU + Trainium(NVIDIA 仍主导但份额下降)
- 极致低延迟推理(Agent、对话) → Groq + Cerebras
- 数据中心规模化降本 → d-Matrix(数字存内)
- 单一爆款模型部署(端侧 API、客服) → Etched + Taalas
- 端侧推理(手机、汽车、IoT) → 苹果 ANE、高通 Hexagon、地平线征程、其他 NPU
互联市场(新出现的细分) — 光子互联会成为「必选项」:
- Lightmatter Passage 系列
- Marvell-Celestial(收购后整合)
- Ayar Labs 光学 I/O
- NVIDIA 自己的 Quantum-X / Spectrum-X 光子交换机
这是个非常少见的产业窗口 — 没有谁取代谁,而是不同方案吃不同细分。这跟「GPU 一统天下」的过去十年是完全不同的格局,也是这一波 AI 推理芯片创业潮真正有意思的地方。
最后一个值得关注的变量 — 大模型架构会变吗?如果 Transformer 在未来 5-7 年内被 Mamba、xLSTM、或者某种全新架构替代,Etched、Taalas 这类「赌单一架构」的方案就会归零;d-Matrix、Groq 会受损但还能撑;Cerebras、TPU、NVIDIA 几乎不受影响。估值梯度的核心逻辑就是市场对这个风险的定价。
如果你信「Transformer 至少还能撑 5 年」 — Etched / Taalas 的押注就是好交易。如果你觉得「3 年内必有新架构」 — 应该把钱押在光谱左侧。这是这条光谱给投资人提供的最核心的决策框架。
参考资料 — 公司资料 · 行业报告 · 技术论文
公司官网与官方公告
- NVIDIA — H100 产品页、DGX B200、GTC 2024 / 2025 主题演讲、Blackwell / Rubin 架构白皮书
- Cerebras — WSE-3 产品页、2026 IPO 招股书(S-1)、OpenAI 100 亿美元合同公告
- Google Cloud — Google Cloud Blog TPU v7 Ironwood 公告(2025)、TPU 8t / 8i 训练推理分化技术博客
- Groq — Groq 官网、LPU TSP 架构白皮书、NVIDIA-Groq 200 亿合作公告(2026)
- d-Matrix — Corsair 产品页、SquadRack 开放标准参考架构、GigaIO 收购公告
- Etched — Etched 官网、Sohu 公告、Llama 70B 500K tok/s 性能数据
- Taalas — 「The Path to Ubiquitous AI」(2026/2)、HC1 产品介绍
- Lightmatter — Lightmatter 官网、Passage M1000 / L200 白皮书、Hot Chips 2025 演讲
- Q.ANT — Q.ANT 官网、NPU 第二代产品资料(2025)、Leibniz 超算中心部署案例
行业报告与新闻
- Deloitte — 2026 AI 工作负载预测(推理占 ~2/3,2027 预计 80%)
- McKinsey — AI 算力市场报告(算力支出 vs 推理占比)
- ServeTheHome — Google TPU v7 Ironwood 报道、Lightmatter Passage Hot Chips 2025 报道、Cerebras WSE-3 评测
- SemiAnalysis — Dylan Patel 的推理芯片深度分析、ASIC vs GPU 经济性测算
- The Information / Bloomberg — NVIDIA-Groq 200 亿交易报道、Marvell-Celestial AI 32.5 亿收购报道、d-Matrix C 轮融资报道
- Jon Peddie Research — Etched 加入俱乐部、Taalas HC1 评估
技术论文与博客
- 脉动阵列原始论文 — Kung, H.T. & Leiserson, C.E.(1979)“Systolic Arrays for VLSI”。脉动阵列概念的奠基性论文,TPU 的理论源头。
- Reck 定理 — Reck, M. et al.(1994)“Experimental realization of any discrete unitary operator”。光子矩阵乘的数学基础,证明任何 N×N 酉矩阵可分解为 N(N-1)/2 个 2×2 旋转矩阵。
- Nature 光子处理器 — 2025 年 Nature Electronics 上的多芯片集成光子处理器论文,达到 65.5 TOPS(16 bit) — 当前光子计算最高水平的代表。
- 存内计算综述 — 2024 年 IEEE Solid-State Circuits Magazine 上的 IMC 综述,涵盖数字 / 模拟 / SRAM / ReRAM 等所有主流方向。
- GPU 架构十年演化 — 本博客的 GPU 架构十年演化与 CUDA 编程模型的同步膨胀,光谱最左侧的 NVIDIA 路线深入拆解。
- LLM 推理底层流程 — 本博客的 LLM 推理过程逐层拆解,理解为什么推理这一阶段适合专用化。