GPU 架构十年演化与 CUDA 编程模型的同步膨胀
如果只用一个数字概括过去十年 NVIDIA 数据中心 GPU 的演进,它是 2380× — 这是 P100 (2016) 到 Rubin R100 (2026) 的 AI 算力提升倍数。同期 CUDA Core 的 FP32 算力只涨了 10×。两个数差出两个数量级,几乎可以说:这十年 NVIDIA 做了一件事 — 把通用算力的预算挪去堆 Tensor Core,再把混合精度卷到 FP4。
但这不是「换了一颗芯片」就完事的。Tensor Core 不是更快的 CUDA Core,它是完全不同拓扑的电路;为了喂饱它,SM 内部新增了 TMA、TMEM、cluster 共享 SMEM;为了让程序员能写出能驾驭它的代码,CUDA 编程模型在 Thread/Block/Grid 三层之间硬塞进了 Warp 和 Cluster 两层。所以同一个 torch.matmul(a, b) 在 V100、A100、H100、B200 上写法完全不变,但底下 cuBLAS 每一代都被 NVIDIA 重写一遍。这篇文章把硬件演化与编程模型膨胀放在一起讲,因为它们是同一件事的两条线索。
概览 — 一张图压缩十年
七代旗舰横向对照 — Pascal · Volta · Turing · Ampere · Hopper · Blackwell · Rubin
七代数据中心 GPU 的横向对照,每一行都是 NVIDIA 战略决策的物理结果:
| 年份 | 架构 | 旗舰卡 | 制程 | 晶体管 | FP32 (CUDA Core) | Tensor Core 主精度 | Tensor Core 最低精度 | HBM | NVLink |
|---|---|---|---|---|---|---|---|---|---|
| 2016 | Pascal | P100 | 16 nm | 15 B | 10.6 TF | — | — (无 TC) | 16 GB HBM2 | 160 GB/s |
| 2017 | Volta | V100 | 12 nm | 21 B | 15.7 TF | 125 TF (FP16) | 125 TF | 32 GB HBM2 | 300 GB/s |
| 2018 | Turing | T4 | 12 nm | 14 B | 8.1 TF | 65 TF (FP16) | 130 TOPS (INT8) | 16 GB GDDR6 | — |
| 2020 | Ampere | A100 | 7 nm | 54 B | 19.5 TF | 312 TF (FP16) | 624 TOPS (INT8) | 80 GB HBM2e | 600 GB/s |
| 2022 | Hopper | H100 | 4 nm | 80 B | 67 TF | 990 TF (FP16) | 1979 TF (FP8) | 80 GB HBM3 | 900 GB/s |
| 2024 | Blackwell | B200 | 4 nm × 2 die | 208 B | 80 TF | 2250 TF (FP16) | 9000 TF (FP4) | 192 GB HBM3e | 1.8 TB/s |
| 2026 | Rubin | R100 | 3 nm | 336 B | ~100 TF | ~8000 TF (FP16) | 50,000 TF (FP4) | 288 GB HBM4 | 3.6 TB/s |
看最右两列,你会看到一个反向剪刀差:CUDA Core FP32 算力从 10.6 → 100 TFLOPS 涨了约 10×;Tensor Core 最低精度从 0 → 50,000 TFLOPS 涨了无穷倍。这两条曲线的剪刀差就是这篇文章的核心叙事。
算力提升从哪里来 — 几何叠加 · 通用 10× · 专用 200×
把 2380× 拆开来看,绝大多数不是「通用算力变快」,而是「围绕矩阵乘的几条专项乘子相乘」。下面这张图把四个独立乘子摆在同一根对数轴上 — 长度越长,贡献越大:
下一步要回答的是 — Tensor Core 凭什么能涨这么快?它跟 CUDA Core 究竟差在哪?为什么是「卷它」而不是「卷 CUDA Core」?这要钻到 SM 内部去看。
SM 内部解剖 — 共享前端 · 五种并列电路
五种并列的执行单元 — 不是「核心 + 多种调度」
一个 SM(Streaming Multiprocessor,流式多处理器) 是 GPU 物理层面的「车间」;一颗 B200 有 148 个 SM。误区是把 SM 想成「一种核心 + 多种调度方式」 — 事实是 SM 内部有五种完全独立的执行单元,平级摆放,共享同一个前端控制 + 同一块寄存器与 SMEM。

这张图里最容易被误读的就是 CUDA Core 与 Tensor Core 的并列关系。一个常见的错误模型是「Tensor Core 内部协调多个 CUDA Core 完成矩阵乘」 — 这是错的。Tensor Core 自己有独立的、专为矩阵乘设计的硅片电路;一颗 B200 SM 里 Tensor Core 占的硅片面积比 CUDA Core 还多。这个判断的反证非常直接:CUDA Core FP32 算力 80 TFLOPS,而 Tensor Core FP16 算力 2250 TFLOPS — 高 28×。如果 Tensor Core 真的是「调度 CUDA Core 实现」,这 28× 从哪儿来?
Warp scheduler 怎么分发指令 — 五条管线物理独立 · 共享前端
更准确的说法是 — warp scheduler 根据指令类型分发到不同管线:fma.f32 走 CUDA Core 管线、mma.sync 走 Tensor Core 管线、ex2.f32 走 SFU 管线、ld.global 走 LD/ST 管线、cuda::memcpy_async 走 TMA 管线。这五条管线物理上完全独立,只是共享前端的取指、解码、寄存器堆。这跟 CPU 里 AVX 单元、标量 ALU、AES 引擎并列的关系完全同构。
CUDA Core vs Tensor Core 的电路差异 — FMA 流水线 vs 脉动阵列
钻到电路层面,两者的差异完全不是「大小」的问题,是拓扑的问题。
标量 FMA 流水线 — CUDA Core 的电路
一个 CUDA Core 是个标量 FMA 单元:一个 24×24-bit 整数乘法器 + 一个 24-bit 加法器 + 流水线寄存器,大约 2-3 万晶体管。一周期吞吐 1 次 FMA(= 2 次浮点运算)。SM 里 128 个 CUDA Core 就是 128 个独立的 FMA 电路并排摆放,每个独立工作。
二维 PE 阵列 — Tensor Core 的电路
一个 Tensor Core 是个二维乘加器阵列,借鉴了 systolic array 的核心思想。数据按时序流入,每个 PE(Processing Element) 同时做一次乘加,结果传给邻居或累加在本地:
为什么相差几百倍 — 三条物理原因
为什么这种拓扑能带来几百倍提升?三条物理原因:
- 数据复用极大化 — A 的一行进入阵列后流经多个 PE,被复用 N 次,带宽放大 N 倍。这就解决了「矩阵乘 arithmetic intensity 高」这个数学事实需要的物理基础。
- 消除控制开销 — CUDA Core 每条 FMA 都要走 warp scheduler → dispatch → register read → execute → writeback,控制开销占 80%+ 能耗。Tensor Core 阵列是硬连线的,一条
mma.sync指令激活整个阵列工作几个周期,期间不需要任何动态调度。 - 局部连线代替全局连线 — 阵列内 PE 之间是短线;CUDA Core 之间通信要走寄存器堆,是长线。短线意味着更高频率、更低功耗、更小面积。
NVIDIA 在专利和论文里故意不公开承认 Tensor Core 是 textbook 意义上的 systolic array(Google TPU 倒是大方承认),内部很可能掺杂了 adder tree 等变体。但这不影响理解 — 关键判断是 「铺一层硬连线的 MAC 阵列」,而不是「一种更快的 FMA」。
电路差异速查表 — 拓扑 · 控制 · 编程粒度
下面这张表帮你把电路差异钉死:
| 维度 | CUDA Core | Tensor Core |
|---|---|---|
| 电路拓扑 | 标量 FMA + 流水线 | 二维 MAC 阵列 + 硬连线数据通路 |
| 一次操作的 MAC 数 | 1 | 几千到几十万(随代际增长) |
| 控制方式 | 动态调度(warp scheduler 每条指令派发) | 硬连线(一条指令激活阵列几周期) |
| 编程粒度 | 每线程独立发指令 | 32 线程组成的 warp 协作发射 |
| 适合工作 | 标量 / 向量 / 控制流 / 激活函数 | 矩阵乘 / 卷积 |
| 硅片面积比 | ~30% | ~40%(B200 SM 估算) |
SFU / TMA / TMEM — 围绕喂饱 Tensor Core 的辅助电路
Tensor Core 算力涨太快,反过来逼出了一连串配套电路。它们不增加 FLOPS,但能保证 Tensor Core「不饿肚子」 — 而饿肚子是 GPU 优化的第一大敌。
SFU — 超越函数硬连线
SFU(Special Function Unit) 处理超越函数 — sin / cos / exp / log / sqrt / rsqrt。电路上是一块小 ROM(预存几十到几千个采样点)加一个乘加器:用输入 x 的高位查表找到两个采样点,用低位做线性或二次插值,几个周期出结果。这比让 CUDA Core 跑泰勒展开多项式快几十倍。代价是精度 — __expf(x) 走 SFU 大概 8-9 位有效精度,expf(x) 走软件实现有完整 23 位。SFU 数量少(每 SM 4 个 vs CUDA Core 128 个,比例 1:32)的原因是它是流水线化的:每周期能接收新指令,4 个 SFU 正好支持一个 warp 不阻塞地执行超越函数。
TMA — 张量异步搬运的专用单元
TMA(Tensor Memory Accelerator) 是 Hopper 引入的「张量搬运专用单元」。它解决的问题是 — 用 LD/ST 搬大张量太浪费:让一个 warp 的 32 个线程各自算地址、循环、加载,指令开销巨大。TMA 把这事抽象成「张量描述符 + 一条指令」:你预先构造一个 tensor map 描述要搬的张量(多维 shape、stride、起始地址),然后一个线程发一条指令,TMA 硬件自己生成地址序列、批量发起内存请求、写入 SMEM,完成后通过 async barrier 通知。这是个带状态机的小处理器,内部含 AGU(Address Generation Unit)、request scheduler、layout transformer。最关键的是 — TMA 是异步的,发指令的线程立刻返回去算别的,数据到位时再同步。这就解锁了 warp specialization 模式 — producer warp 一直发 TMA,consumer warp 一直算 Tensor Core,两者完全重叠。
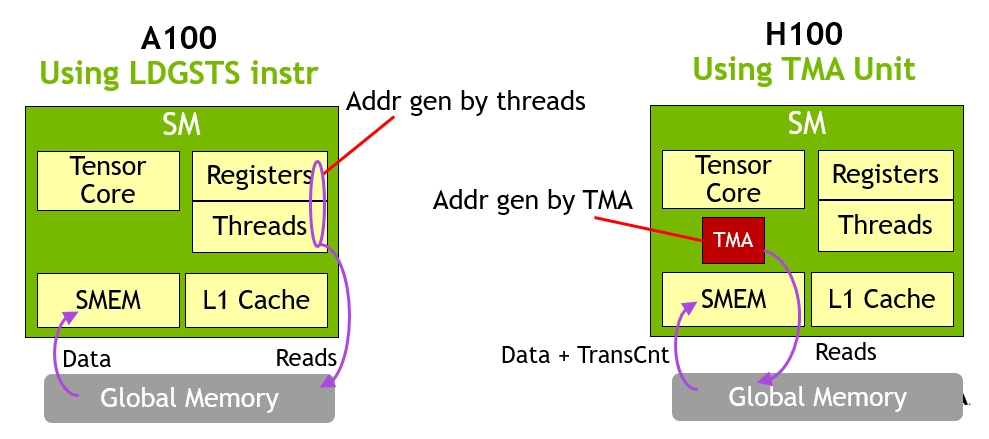
LDGSTS 指令搬张量,需要 warp 内每个线程算地址、发 load。右:Hopper H100 起一个线程发一条 TMA 指令,整块张量异步搬到 SMEM,其余线程同时去算 Tensor Core。这正是 warp specialization 的物理基础。TMEM — Tensor Core 专用累加内存 · Blackwell 起
TMEM(Tensor Memory) 是 Blackwell 才出现的 — 256 KB 的 Tensor Core 专用 SRAM,绑在 SM 内部。它解决的是更深一层的瓶颈 — 当 Tensor Core 算力涨到几千 PFLOPS 时,连寄存器堆都喂不饱。Hopper 之前 mma 的操作数和累加器都在 warp 32 个线程的寄存器里,寄存器堆的端口带宽成了瓶颈。Blackwell 引入 TMEM,操作数和累加器直接放在专用 SRAM 里,新指令 tcgen05.mma 操作数明确指向 TMEM 而非寄存器,彻底绕过寄存器端口。这就是为什么 Blackwell 在 FP64 GEMM 上能跑到理论峰值的 80.7%(H200 同样规模只到 55.6%)。
| 单元 | 作用 | 电路本质 | 引入代际 |
|---|---|---|---|
| SFU | 超越函数 | ROM + 插值乘加器 | Volta 之前就有 |
| TMA | 张量异步搬运 | AGU + 状态机 + layout 转换 | Hopper |
| TMEM | Tensor Core 专用累加内存 | 独立 SRAM + 专用读写端口 | Blackwell |
这三件事合起来,讲了同一个故事 — Tensor Core 越强,围绕它的辅助电路就越多越专用。这是「专用化阶梯」越往上爬越窄的物理体现。
内存层次 — 显式管理是 GPU 的本质特色
显式 vs 隐式的边界 — CPU 让你忘 · GPU 让你直面
GPU 的存储层次远比 CPU 复杂,核心差异不在「层数」,而在 「显式」与「隐式」的边界。CPU 让你忘记缓存的存在 — 写 int x = arr[i],硬件自动从 cache 取数据。GPU 强迫你直面 — 写 __shared__ float tile[256] 声明,然后必须显式 tile[tid] = gmem[idx] 把数据搬进去,再 __syncthreads() 等待。
为什么显式管理是必须的 — 一个 SM 跑 2048 个线程
显式管理为什么对 GPU 是必须的?因为 GPU 一个 SM 同时跑 64 个 warp × 32 线程 = 2048 个线程,根本没法给每个线程配 cache + 预取器。CPU 一个核心服务一个线程,给它配几兆 cache 完全 OK;GPU 每线程能分到的硬件资源少得多,只能让线程之间显式组织数据共享 — 这就是 SMEM 必须存在的根本原因。
管理方式速查表 — 分配 · 搬运 · 访问 · 释放
| 存储 | 分配 | 数据搬运 | 访问 | 释放 |
|---|---|---|---|---|
| 寄存器 | 编译器自动 | — | 隐式 | 自动 |
| SMEM | 程序员声明 | 程序员手动搬 | 隐式 | 自动(block 结束) |
| TMEM | 程序员显式 alloc | 程序员搬 | 通过 tcgen05 指令 | 程序员 dealloc |
| Constant | 程序员声明 | 程序员一次性灌入 | 隐式 | 自动 |
| L1 / L2 | — | 硬件自动 | 隐式 | — |
| GMEM | cudaMalloc | cudaMemcpy | 隐式 | cudaFree |
| 其他 GPU HBM | NCCL 分配 | NCCL/NVSHMEM | 通过 API | NCCL 释放 |
整个 GPU 性能优化的本质,就是 — 让数据尽量留在层次的上半部分(寄存器/SMEM/TMEM/L2),少回 HBM。kernel fusion、FlashAttention、CUTLASS、warp specialization,所有这些技术的核心都是这一件事。
精度演化 — FP4 不是省钱 · 是把芯片当 4 颗用
为什么要下移精度 — 同硅片塞更多 MAC
混合精度是这十年算力提升的第二条主线 — 与 Tensor Core 拓扑并列。每一代都引入一种更低的精度,理由不是「省钱」,是 把同样硅片当多颗用。
物理基础 — 乘法器面积 ∝ 位宽²
物理上的根本原因:乘法器的面积大致正比于位宽的平方。
- FP32 乘法器:24×24-bit 整数乘法器(隐含 1 位) → 面积单位 1
- FP16 乘法器:~11×11 → 面积约 1/5
- FP8 乘法器:~5×5 → 面积约 1/25
- FP4 乘法器:~2×2 → 面积约 1/144
同样的硅片面积,FP4 乘法器能塞下的数量是 FP32 的 100 倍以上。换种说法 — FP4 不是「便宜的 FP16」,而是「同样硅片塞 4 倍 MAC」。
下面是 B200 上各精度的 Tensor Core 算力对照:
| 精度 | 输入位宽 | 累加 | B200 算力 | 相对 FP32 倍数 |
|---|---|---|---|---|
| FP32 (CUDA Core) | 32-bit | 32-bit | 80 TFLOPS | 1× |
| TF32 (Tensor Core) | 19-bit 实效 | 32-bit | ~1,100 TFLOPS | ~14× |
| FP16 / BF16 (Tensor Core) | 16-bit | 32-bit | 2,250 TFLOPS | 28× |
| FP8 (E4M3 / E5M2) | 8-bit | 32-bit | 4,500 TFLOPS | 56× |
| FP6 (E3M2 / E2M3) | 6-bit | 32-bit | ~6,750 TFLOPS | 84× |
| FP4 (E2M1) | 4-bit | FP32 或 FP16 | 9,000 TFLOPS | 112× |
| FP4 + 2:4 稀疏 | 4-bit | FP32 或 FP16 | 18,000 TFLOPS | 225× |
| FP64 (Tensor Core) | 64-bit | 64-bit | 40 TFLOPS | 0.5× |
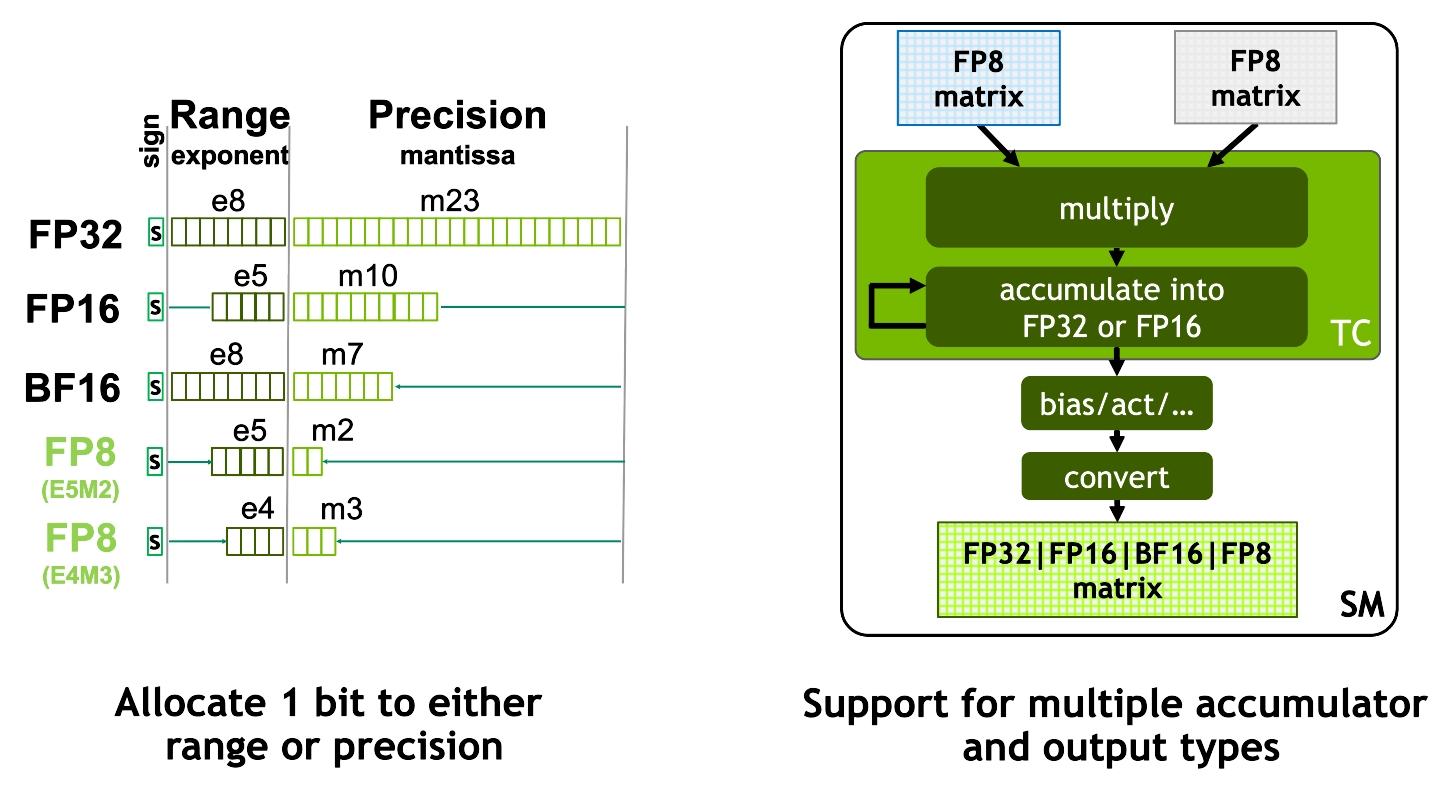
注意 — Tensor Core 并不只跑低精度。它也支持 FP32(走 TF32 模式)、FP64(HPC 用)。但低精度算力远远高于高精度,这是性能/精度的主动权衡,不是能力限制。
代际新增的精度 — 每代下移一级
每一代新增的精度,对应的硬件代际:
| 代际 | 年份 | 新增精度 | 主要驱动场景 |
|---|---|---|---|
| Volta | 2017 | FP16 (Tensor Core 首次) | 训练 |
| Turing | 2018 | INT8 / INT4 | 推理量化 |
| Ampere | 2020 | TF32 / BF16 / 2:4 稀疏 | 训练数值稳定 + 自动加速 |
| Hopper | 2022 | FP8 (E4M3 + E5M2) | LLM 训练 + 推理 |
| Blackwell | 2024 | FP6 + FP4 + microscaling | LLM 推理极致吞吐 |
| Rubin | 2026 | 优化 FP4 + 更多 microscaling | Agent / reasoning 推理 |
每代新增一种精度 — 但能不能用起来是另一回事。FP8 从 H100 发布(2022)到生产可用(2024)用了两年,主要靠 NVIDIA 的 Transformer Engine 库做自动 scaling factor 管理。FP4 也类似 — 硬件支持容易,数值稳定是软件的工作。
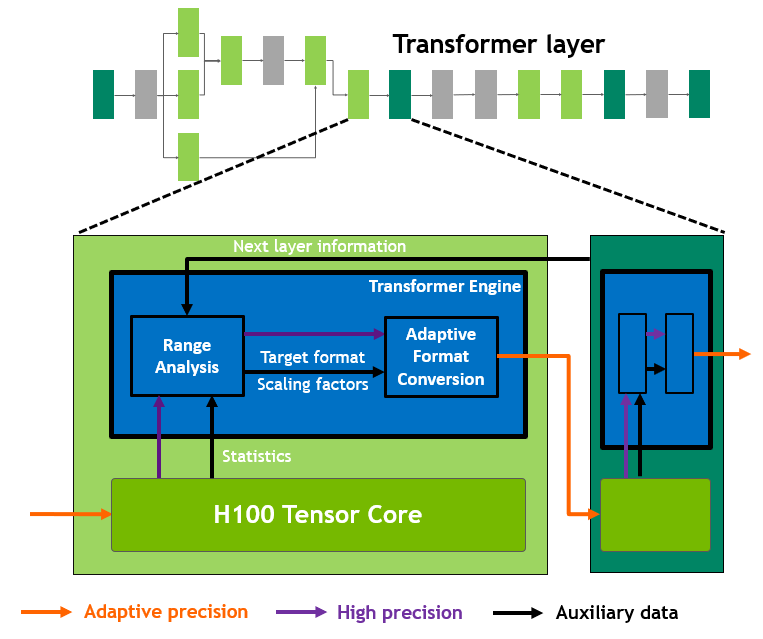
TF32 与 Transformer Engine — 不改代码而悄悄加速
TF32 是个特别值得品味的设计。它对程序员的接口是 FP32(8 位指数 + 24 位尾数,与 IEEE FP32 相同),但内部把尾数截到 10 位(与 FP16 相同)、保留 8 位指数。于是同样一段 cublasSgemm 调用 — 用户什么都不改,FP32 矩阵乘自动走 Tensor Core,速度比真 FP32 快 ~14 倍,精度损失对深度学习几乎无感。这是 NVIDIA 让 Tensor Core 「悄悄接管所有 FP32 矩阵乘」的精妙之处。
代际深度变迁 — Pascal · Volta · Turing · Ampere · Hopper · Blackwell · Rubin
把这十年逐代拆开看,每一代都恰好对应一个 AI 工作负载的时代转折:
Pascal · Volta · Turing — 2016-2018 · Tensor Core 时代开启
Pascal (2016, P100) — 数据中心 GPU 元年。第一次抛弃 GDDR 用 HBM2(720 GB/s),第一次引入 NVLink(160 GB/s,~PCIe 5 倍),第一次原生 FP16(走 CUDA Core,2× FP32 吞吐)。还没有 Tensor Core。这一代证明了「GPU 进数据中心训深度学习」这件事的商业可行。GPT-2 / BERT 时代的训练几乎都在 P100 上跑过。
Volta (2017, V100) — Tensor Core 时代开启。第一代 Tensor Core 每 SM 8 个,做 4×4×4 FP16 矩阵乘,带来 12× 训练加速。这是 GPU 设计哲学的根本转变 — 从「通用并行计算芯片」变成「专为矩阵乘加速的 AI 芯片」。从这一代开始,每代的算力提升主要来自 Tensor Core,而非 CUDA Core。GPT-3 最初就是在 V100 集群上训出来的。
Turing (2018, T4 + RTX 20) — 推理市场分化。T4 是低功耗(70W),引入 INT8 Tensor Core,主打推理服务;同代消费 RTX 20 系列引入 RT Core(光追硬件)。证明了「训练用 V100、推理用 T4」的差异化策略可行。
Ampere · Hopper — 2020-2022 · LLM 训练工业化
Ampere (2020, A100) — LLM 训练工业化。第三代 Tensor Core 引入 TF32(让大量 FP32 代码自动加速,几乎不改代码)、BF16(数值范围更大,训练更稳)、2:4 结构化稀疏(再翻倍吞吐)。新增 MIG(一颗 A100 切 7 个小 GPU)、第二代 NVLink(600 GB/s)、HBM2e。A100 是 NVIDIA 最长青的卡 — 直到 2026 年仍在大量数据中心服役。
Hopper (2022, H100) — Transformer 专用化。第四代 Tensor Core + Transformer Engine 软件层 = 首次原生 FP8 + 自动量化。引入 TMA 解决「Tensor Core 太快、寄存器搬不过来」、引入 Thread Block Cluster 让多个 SM 协同(8 个 block 一个 cluster,共享分布式 SMEM)。NVLink 3 (900 GB/s) + HBM3 (3 TB/s)。H100 在 Transformer 训练上比 A100 快 6-9×。Grace-Hopper Superchip (GH200) 第一次让 CPU 和 GPU 通过 NVLink-C2C 紧耦合。
Blackwell · Rubin — 2024-2026 · 多 die + FP4 + 平台
Blackwell (2024, B200) — 双 die + FP4 时代。第一次双 die 设计 — 两个 reticle-limit die 通过 10 TB/s 内部互联,对软件呈现为单一 GPU,共 208 B 晶体管。第五代 Tensor Core 原生 FP4 / FP6,配合第二代 Transformer Engine 的 micro-tensor scaling。引入 TMEM(256 KB Tensor Core 专用 SRAM)、2-CTA Cluster(两个 SM 共喂一个 Tensor Core 的 UMMA)、解压缩引擎(LZ4/Snappy/Deflate,服务数据分析)。NVLink 5 (1.8 TB/s) + HBM3e (8 TB/s, 192 GB)。GB200 NVL72 把 72 颗 B200 + 36 颗 Grace CPU 整合到一个机柜。
Rubin (2026, R100) — 平台时代。336 B 晶体管,真正的多 die 设计(两个计算 die + 两个 I/O die)。HBM4 (288 GB, 22 TB/s 带宽,~2.8× B200)。224 SM/GPU,FP4 算力 50 PFLOPS(稀疏)。NVLink 6 (3.6 TB/s/GPU)。最关键的变化是哲学层面 — NVIDIA 不再卖 GPU,卖整个机柜级 AI 计算平台,Vera Rubin 平台围绕「七芯片协同」组织(R100 GPU + Vera CPU + NVLink 6 Switch + ConnectX-9 + BlueField-4 + Spectrum-6 + 整合的 Groq 3 LPU)。
十年主线归纳 — 精度 · 阵列 · 存储 · 互联 · 商业形态
把十年放在同一张表里,主线非常清晰:
| 主线 | 体现 |
|---|---|
| 精度下移 | FP16 → INT8 → BF16 → FP8 → FP4,每代加一种 |
| Tensor Core 阵列规模 | 4×4×4 → 16×16×16 → 64×8×16 → 128×256×16 |
| 片上存储显式化 | SMEM 扩大 → cp.async → TMA → Cluster → 分布式 SMEM → TMEM |
| 互联指数增长 | NVLink 160 GB/s → 3600 GB/s · HBM 720 GB/s → 22 TB/s |
| 商业形态 | 卖 GPU → 卖 DGX → 卖机柜 → 卖 AI 工厂 |
CUDA Core 在这张表里几乎缺席 — 它的 FP32 算力从 10.6 → 100 TFLOPS,十年只涨 10×。通用算力让位给专用算力,是这十年最直接的判断。
编程模型同步膨胀 — Thread → Warp → Block → Cluster → Grid
从三层到五层 — Warp 与 Cluster 被塞进中间
硬件复杂度涨上去,程序员看到的编程模型也跟着膨胀。最经典的 CUDA 编程模型是三层 — Thread / Block / Grid:每个线程独立、Block 内线程共享 SMEM、Grid 是所有 Block。但 Tensor Core 时代之后,中间硬塞进 Warp 与 Cluster 两层,变成五层:
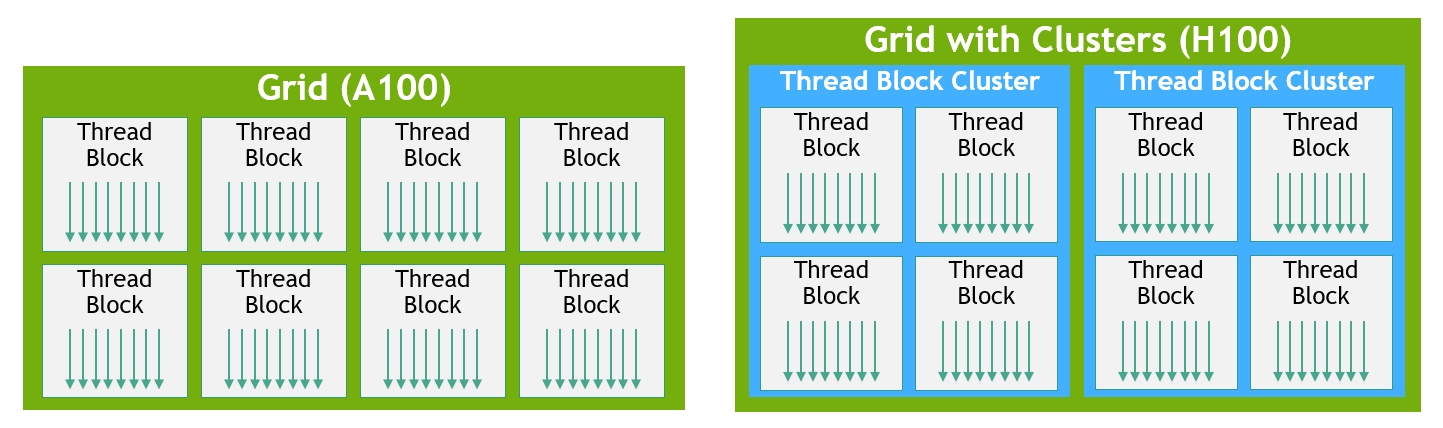
为什么 Warp 必须显式化 — mma.sync 物理上是 warp 级指令
为什么 Tensor Core 时代非要把 Warp 显式化?因为 mma.sync 这条指令物理上就是 warp 级的 — 32 个线程必须协作发射,矩阵 A、B 的元素按特定布局分散在这 32 个线程的寄存器里,Tensor Core 硬件把所有线程的寄存器内容收集起来喂给阵列。一个 16×16×16 矩阵乘需要 512 个 FP16 输入 = 1024 字节,单个线程的寄存器装不下 — 必须分摊到 32 个线程。所以程序员必须从「我这个线程算什么」升级到「我们这个 warp 一起算什么」。
Cluster 的引入逻辑 — 多个 SM 协同喂一个 mma
Cluster 的引入逻辑类似 — Hopper 起 Tensor Core 算力涨到需要多个 SM 一起喂数据,所以引入 cluster 让 block 在 GPC 内有共享 SMEM(distributed SMEM)、共享 TMA。Blackwell 的 2-CTA cluster 进一步把两个 SM 绑成一组共喂一个 UMMA Tensor Core 指令。
代码对照 — naive matmul → wmma → wgmma+TMA → tcgen05+TMEM
最直观的体感是看同一个任务(矩阵乘)的代码怎么随着代际膨胀。下面四段代码依次展示了 Pascal → Volta-Ampere → Hopper → Blackwell 时代写 matmul 的典型样貌。
Pascal · 朴素 thread 级 — 每线程算一个元素
__global__ void matmul_naive(float* A, float* B, float* C, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row >= N || col >= N) return;
float sum = 0;
for (int k = 0; k < N; k++) {
sum += A[row * N + k] * B[k * N + col];
}
C[row * N + col] = sum;
}思考粒度:单个线程。每个线程算 C 里的一个元素,循环 N 次内积。代码可读性极高 — 但性能只有理论峰值的 5-10%(因为完全没用 Tensor Core,数据也直接从 GMEM 读)。
Volta–Ampere · wmma fragment — Warp 协作 · Tensor Core 首次
#include <mma.h>
using namespace nvcuda::wmma;
__global__ void matmul_wmma(half* A, half* B, float* C, int N) {
__shared__ half tile_A[16][16];
__shared__ half tile_B[16][16];
// fragment 分布在整个 warp 32 个线程的寄存器里
fragment<matrix_a, 16, 16, 16, half, row_major> a_frag;
fragment<matrix_b, 16, 16, 16, half, col_major> b_frag;
fragment<accumulator, 16, 16, 16, float> c_frag;
fill_fragment(c_frag, 0.0f);
for (int k = 0; k < N; k += 16) {
// 异步加载到 SMEM(Ampere 起的 cp.async)
// ... 省略加载逻辑 ...
__syncthreads();
load_matrix_sync(a_frag, &tile_A[0][0], 16); // warp 协作
load_matrix_sync(b_frag, &tile_B[0][0], 16);
mma_sync(c_frag, a_frag, b_frag, c_frag); // 一条指令 = 16×16×16 矩阵乘
__syncthreads();
}
store_matrix_sync(&C[...], c_frag, N, mem_row_major);
}思考粒度升级到整个 warp。注意几个关键变化 — 所有 wmma API 带 _sync 后缀,意味着「整个 warp 必须一起调用、必须同步执行」;代码里完全没有 threadIdx — fragment 把线程级的复杂度隐藏起来;混合精度首次出现(输入 half,累加 float)。性能能跑到峰值 60-80%。
Hopper · TMA + warp specialization — producer / consumer 流水重叠
// 极度简化版 — 真实 CUTLASS 代码长几倍
__global__ void matmul_hopper(...) {
__shared__ AsyncBarrier bar;
extern __shared__ half smem_buffer[];
int warpId = threadIdx.x / 32;
if (warpId == 0) {
// Producer warp — 只发 TMA 指令搬数据,不算
for (int k = 0; k < N; k += TILE_K) {
cuda::memcpy_async(smem_A, gmem_A_tile, tma_desc_A, bar);
cuda::memcpy_async(smem_B, gmem_B_tile, tma_desc_B, bar);
bar.arrive();
}
} else {
// Consumer warps — 只算 Tensor Core,不搬
for (int k = 0; k < N; k += TILE_K) {
bar.wait(); // 等数据到位
wgmma::mma_async(c_frag, smem_A, smem_B); // 异步 mma!
wgmma::commit_group();
wgmma::wait_group<0>();
}
}
}思考粒度再升级 — warp specialization。不同 warp 干完全不同的活 — 有的专门搬数据(producer),有的专门算 Tensor Core(consumer),两条流水通过 async barrier 同步。wgmma(warpgroup MMA)替代 wmma,操作数可以直接来自 SMEM 而不必先加载到寄存器。async barrier 不数线程,数字节数 — 「我等 16 KB 数据到位」。性能能跑到峰值 85-95%,但这种代码已经基本只有 CUTLASS / FlashAttention 团队能直接写。
Blackwell · tcgen05 + TMEM — 2-CTA cluster · 操作数绕过寄存器
__global__ void matmul_blackwell(...) {
// TMEM 显式分配
auto tmem_c = tcgen05::alloc<float, 128>();
__shared__ AsyncBarrier bar;
if (in_producer_warp) {
// TMA multicast — 一次加载,2-CTA cluster 内的两个 SM 都收到
cuda::memcpy_async_tma_multicast(smem_A, gmem_A, cluster);
cuda::memcpy_async_tma_multicast(smem_B, gmem_B, cluster);
} else {
// 操作数来自 SMEM,结果写入 TMEM(不抢寄存器)
tcgen05::mma(tmem_c, smem_A, smem_B);
tcgen05::commit();
}
// 从 TMEM 取出结果
tcgen05::load(c_reg, tmem_c);
tcgen05::dealloc(tmem_c);
}又多一层手动管理 — TMEM 显式 alloc / dealloc。tcgen05.mma 指令的操作数来自 SMEM、累加器在 TMEM,彻底绕过寄存器堆。2-CTA cluster 让两个相邻 SM 通过 distributed SMEM + TMA multicast 共喂一个 mma。一次激活整个 cluster 的工作量非常大。
代际复杂度对照 — 每代代码量翻 2-3 倍
把这四段代码摆在一起,演化趋势一目了然:
| 代际 | 思考粒度 | 新增的「程序员要操心的事」 | 代码量级 |
|---|---|---|---|
| Pascal 之前 | Thread | thread / block / grid 三件套 | ~20 行 |
| Ampere | + Warp | fragment 布局 / _sync 语义 / cp.async | ~100 行 |
| Hopper | + Cluster | TMA descriptor / warp specialization / async barrier | ~300 行 |
| Blackwell | (Cluster 升级) | TMEM alloc/dealloc / tcgen05 / 2-CTA / multicast | ~500 行 |
每代复杂度大致翻 2-3 倍。但这只是直接写裸 CUDA 的视角 — 真实世界里 90% 的人不写这种代码。
抽象层吸收复杂度 — torch.matmul 不变 · 底下 cuBLAS 每代重写
五层用户的代码量级 — 从 1 行到 1000 行汇编
这才是 NVIDIA 设计哲学的精髓 — 硬件复杂度暴涨,被层层抽象吸收,普通用户体验保持稳定甚至变简单。
同样的矩阵乘任务,不同人群实际写的代码量级:
| 用户群体 | 调用方式 | 代码量级 | 性能 | 需要懂什么 |
|---|---|---|---|---|
| 普通 AI 工程师 | torch.matmul(a, b) | 1 行 | 接近峰值 | 几乎什么都不用懂 |
| 自定义算子工程师 | Triton @triton.jit + tl.dot | ~50 行 Python | 80-95% 峰值 | tile 划分 / SMEM 概念 |
| 高性能库开发者 | CUTLASS 模板 | ~100 行 C++ | 接近峰值 | Tensor Core / CuTe layout |
| 裸 CUDA 工程师 | 直接 mma.sync | ~300 行 C++ | 取决于功力 | warp / SMEM bank / mma 指令 |
| 极致优化者 | 内联 PTX | ~1000 行汇编 | 理论极限 | 寄存器分配 / 指令调度 / 依赖追踪 |
越往下,控制力越强,但工作量爆炸。FlashAttention 作者 Tri Dao 写的就是裸 CUDA + 内联 PTX 那一层,所以一个人能比 cuBLAS 团队的某些 kernel 还快。但绝大多数 AI 工程师只在最顶上那一层。
为什么手写不一定比 cuBLAS 快 — NVIDIA 的护城河不止硬件
一个有趣的反转 — 90% 的情况下,PyTorch + cuBLAS 比一个普通工程师手写的 CUDA 快得多。原因有三个:
- cuBLAS 是 NVIDIA 工程师专门为每代 GPU 调优的,他们知道 Tensor Core 的每个细节(包括没公开的)。
- cuBLAS 内部有一个算子库 — 同一个 matmul 可能有几十种 kernel 实现,运行时根据矩阵形状自动挑最优。
- 普通人很难想到的优化 — double buffering、warp specialization、bank conflict 规避、寄存器压力平衡。
所以 NVIDIA 的护城河不只是硬件,更是这一整套从顶到底的软件栈。这也是为什么 AMD GPU 性能数字上能追平甚至超过 NVIDIA,但生态上还差一大截 — 硬件可以追,这十几年积累的库和编译器追不上。
软件栈与开源版图 — 开源的外壳 · 闭源的核心
CUDA 软件栈分层 — L7 框架 → L1 硬件 · 七层切片
把这十几年沉淀的 CUDA 库生态画出来,你会看到一个反直觉的事实 — 最核心、用得最多的几个库恰恰是闭源的,开源的都是上层、外围、面向定制化的部分。
开源 / 闭源边界 — 最常用的几个库恰恰是闭源
很多人误以为 cuBLAS、cuDNN 是开源的 — 实际上它们是 NVIDIA 最严密保护的产品。pip install nvidia-cublas-cu12 装的不是源码,是预编译好的 .so 二进制文件,license 字段明确写 LicenseRef-NVIDIA-Proprietary。
| 库 | 开源状态 | License | 你能看到什么 |
|---|---|---|---|
| CUDA Runtime / Driver | ❌ 闭源 | NVIDIA Proprietary | 只有 header 和 .so |
| cuBLAS / cuBLASLt | ❌ 闭源 | NVIDIA Proprietary | 只有 header 和 .so |
| cuDNN(核心) | ❌ 闭源 | NVIDIA Proprietary | 只有 header 和 .so |
| cuDNN Frontend(C++ wrapper) | ✅ 开源 | MIT | wrapper,调用闭源 cuDNN |
| cuFFT / cuSPARSE / cuSOLVER | ❌ 闭源 | NVIDIA Proprietary | 只有 header 和 .so |
| CUTLASS | ✅ 完全开源 | BSD-3-Clause | 全部 C++ 模板源码 |
| Triton(OpenAI) | ✅ 完全开源 | MIT | 全部源码 |
| NCCL | ✅ 完全开源 | BSD-3 | 全部源码 |
| NVSHMEM(2024 后) | ✅ 开源 | BSD-3 | 全部源码 |
| Transformer Engine | ✅ 完全开源 | Apache 2.0 | 全部源码 |
| TensorRT | ⚠️ 部分开源 | Apache 2.0(plugins) | 仅 plugins、parsers,核心闭源 |
| TensorRT-LLM | ⚠️ 部分开源 | Apache 2.0(前端) | 前端 Python,依赖闭源 TensorRT |
| RAPIDS(cuDF / cuML) | ✅ 完全开源 | Apache 2.0 | 全部源码 |
| Megatron-Core / NeMo | ✅ 完全开源 | Apache 2.0 | 全部源码 |
真正的护城河 — 不是单库 · 是十几年的生态
NVIDIA 用「开源的外壳 + 闭源的核心」这种产品策略:让用户能扩展(写自定义 plugin、改 CUTLASS 模板、定制 NCCL 通信),但不能复制核心实现。AMD ROCm 哪怕把对应库全部开源(rocBLAS / MIOpen 都是开源的),性能上仍然落后 cuBLAS / cuDNN 2-3 年 — 因为 cuBLAS / cuDNN 的优化技巧(用 Tensor Core 的最新指令、调度 warp、用 TMA)藏在二进制里,AMD 没法「抄」,只能逆向工程或重新发明。
这就是 NVIDIA 真正的护城河 — 不只是某一个库,是几十个库十几年积累的整体生态。
总结 — 卷 Tensor Core · 卷精度 · 卷抽象层
三条主线 — Tensor Core · 精度 · 抽象层
把十年浓缩成一句话:NVIDIA 这十年只做了三件事 — 卷 Tensor Core、卷混合精度、卷抽象层吸收复杂度。
具体说:
- 卷 Tensor Core — 算力提升的几乎全部来自这里。一颗 B200 上 Tensor Core 比 CUDA Core 算力高 ~60-250 倍。它不是更快的 CUDA Core,是完全不同电路拓扑的 systolic-like 阵列。
- 卷精度 — 每代下探一级。FP32 → TF32 → FP16/BF16 → FP8 → FP4。每降一次精度,同样硅片能塞 4 倍 MAC,LLM 推理吞吐免费翻倍。
- 卷抽象层 —
torch.matmul(a, b)一行没变,底下 cuBLAS / cuDNN 每代被 NVIDIA 重写。CUTLASS / Triton / Transformer Engine 把硬件复杂度吃掉,让用户保持「写 PyTorch 就够了」的体验。
为什么是 Tensor Core — 物理 · 架构 · 商业三层原因
如果再追问「为什么是 Tensor Core 而不是 CUDA Core」 — 答案在三层:
- 物理层 — CUDA Core 接近频率上限,堆 SM 数量受功耗散热制约;Tensor Core 还有精度下移和阵列规模放大两条路可走。
- 架构层 — Tensor Core 的硬连线控制让控制开销几乎为零,同样硅片做的有效计算多得多。
- 商业层 — Tensor Core + 闭源 cuBLAS / cuDNN 是 NVIDIA 真正的护城河,AMD 硬件再快也复制不了这套软件栈。
未来 5 年的展望 — FP2 · 更大 Cluster · 平台化
未来 5 年这条线还会继续走 — Rubin Ultra (2027) / Feynman (2028) 已经在路线图上,FP2 / INT2 可能再下一代出现,Cluster 可能从 8-16 block 扩到几十,TMEM 可能进一步分化出更多专用存储。但对你而言,这条主线一旦抓住,以后看任何 NVIDIA 新闻、新架构、新产品 — 都能立刻判断它的本质是什么:它无非是在「卷 Tensor Core / 卷精度 / 卷抽象层」这三条线上的某一处再加一刀。
参考资料 — 白皮书 · 论文 · 文档
白皮书与官方文档
- NVIDIA 架构白皮书 — 每代发布时 NVIDIA 都会出一份非常详细的架构白皮书(Architecture Whitepaper),是最权威的一手资料。建议至少读 Hopper 与 Blackwell 这两份。
- CUDA C++ Programming Guide — 官方手册的第 3 章异步拷贝、第 5 章 Tensor Core、第 7 章 cluster,讲编程模型膨胀的具体语法。
- CUTLASS GitHub — 最新的 CUTLASS 4.x + CuTe DSL,是把所有架构特性用到极致的最权威开源实现。github.com/NVIDIA/cutlass
论文与工程博客
- Tri Dao FlashAttention 系列论文 — FlashAttention(2022)/ FA-2(2023)/ FA-3(2024)。把 TMA + warp specialization + Tensor Core 串起来用的范本,FA-3 几乎用尽了 Hopper 的所有新特性。
- Colfax Research 的 TMA / wgmma 教程 — 工程层面把 Hopper 的 TMA、wgmma、async barrier 讲得最清楚的系列博客。
- Aleksa Gordić 的「matmul anatomy」博客 — 把 matmul kernel 从朴素版到 CUTLASS 版的演化逐步推导,是入门到进阶最好的连续读物之一。
教科书与课程
- 《Programming Massively Parallel Processors》(Kirk & Hwu) — GPU 并行编程教科书,从硬件到 CUDA 到分布式都有覆盖。第 5 版起加了大量 Volta-Ampere 时代的内容。
- CMU 15-418 / Stanford CS149 — 这两门课的讲义和作业都是公开的,把并行架构、SIMT、内存模型讲得比绝大多数书籍清楚。