CPU vs GPU 分布式计算 — 同一套 BSP 理论的两套工程实现
Spark 里 reduceByKey 把分散在几十台机器上的键值聚合起来 — 单次调用毫秒到秒级;PyTorch DDP 训练里 loss.backward() 触发的 NCCL AllReduce 把几千张 GPU 上的梯度求和 — 单次调用几十微秒。两个操作名字几乎一样,实际差出两到三个数量级。但更反常的是:它们的核心数学完全相同。
这不是巧合,是同源。这套术语早在 1994 年 MPI 标准里就定死了 — MPI_Reduce、MPI_AllReduce、MPI_Bcast、MPI_AllGather、MPI_Alltoall。30 年里这套原语沿着两条支流演化:一条进了 Hadoop / Spark 这种廉价容错商用集群世界,一条进了 MPI / NCCL 这种紧耦合 HPC / GPU 训练世界。理论完全统一,但工程约束截然不同 — 容错策略、通信粒度、同步频率、编程模型、硬件互联,每一项都差出一两个数量级。
这篇文章用一条主线把两个世界对照起来 — 同一套数学,两套工程。能理解到这个层次,你看 Spark 的 shuffle 和看 NCCL 的 AllReduce 就是看同一件事的两种约束实现;你跨领域迁移知识(从 Spark 工程师跳到分布式 ML 工程师)的成本会指数级降低 — 因为认知框架已经建立。
共同祖先 — MPI 1994 · BSP 1990
这套术语为什么会重叠?因为它们都流自同两个源头:BSP (Bulk Synchronous Parallel) 模型 和 MPI (Message Passing Interface) 标准。前者是 Leslie Valiant 1990 年提出的并行计算理论模型,把所有并行算法抽象成「本地计算 → 通信 → 全局同步」的循环超步;后者是 1994 年定的并行编程接口标准,定义了一组集合通信原语。BSP 给了理论框架,MPI 给了 API 名字,两者一起塑造了过去 30 年所有大规模并行计算系统。
这棵树解释了第一个疑惑 — 为什么 Spark 与 NCCL 共用 reduce / allreduce / broadcast / gather 等术语。它们都源自 MPI;MPI 给了一组标准化的「集合通信原语」,后来不管是廉价集群、超算、还是 GPU 训练,都重用了这套词汇。
但这棵树也埋下了第二个疑惑 — 既然术语相同,为什么实现差这么远?答案在分支的工程约束 — 当 Hadoop 把 MPI 思路搬到「上万台便宜机器、每天都有几台挂掉」的场景,容错变成了头号需求;当 NCCL 把 MPI 思路搬到「8 张 GPU 通过 NVLink 全互联、每个 step 几十微秒」的场景,极致带宽变成了头号需求。两种约束完全不同,工程实现自然发散。
BSP 模型 — 本地计算 → 通信 → 全局同步
把上面所有系统都画成同一张图,你能直接看出 BSP 模型是怎么统一所有人的:
把这四种系统并排画在 BSP 框架里,差异就一目了然了 — 三段式骨架完全相同,绝对时间差几个数量级。这就是「同 BSP 理论、差工程约束」的本质。一个 PyTorch DDP step 大约毫秒级,一个 Spark stage 大约分钟级,差三个数量级,但都是「本地计算 → 通信 → 全局同步 → 下一超步」的循环。
这就解释了为什么这两个领域的术语会重叠 — 它们结构上是同一种东西,具体参数(延迟、带宽、容错、粒度)不同而已。
单机内的”分布式” — CPU 乱序引擎 vs GPU warp scheduler
「分布式」这个词不只用于多机 — 单机内多个执行单元如何协作,也是同一套问题。这里 CPU 和 GPU 的设计哲学完全相反:CPU 把调度复杂度全藏进硬件,GPU 把调度极度简化、靠并行规模隐藏延迟。
| 维度 | CPU 乱序引擎 | GPU Warp Scheduler |
|---|---|---|
| Branch Predictor | 现代 CPU 95%+ 准确率,猜错 rollback 几十周期 | 无。warp 内分支不一致直接 warp divergence 串行 |
| Reorder Buffer (ROB) | Intel Golden Cove 512 条目,挖深度并行 | 无。每个 warp 严格顺序执行 |
| Reservation Station | 复杂依赖追踪 + 端口分配 | 极简。只挑「操作数到位的 warp」发出去 |
| Register Renaming | 几百个物理寄存器消除假依赖 | 无。每 warp 自己的物理寄存器分配 |
| Speculative Execution | 预测后抢跑预测路径 | 无 |
| 隐藏访存延迟 | 单线程内挖 ILP,乱序覆盖几百周期延迟 | 直接切换到另一个 warp,SM 同时有 64 warp 可切 |
| 硅片面积占比 | 约 50% 给调度逻辑 | 约 10% 给调度,90% 给执行单元 |
CPU 一个核心 50% 的硅给调度,真正干活的 ALU 只占小头。GPU SM 反过来,调度只占小角落,绝大部分面积给 CUDA Core / Tensor Core / SFU / TMA 这些执行单元。这就是为什么同样硅片面积,GPU AI 算力是 CPU 的几十上百倍 — 它把 CPU 砍掉的调度面积全用来堆 ALU。
设计哲学的根本对立用一句话概括:
CPU 解决「单线程要快」 — 一个程序里可挖的并行有限,所以靠复杂硬件挖每一滴 ILP。 GPU 解决「线程多就是快」 — 硬件不愁找不到独立指令(下一条来自另一个 warp 就行),所以调度极简。
这一对哲学决定了两边的所有其他设计 — 从内存层次到执行单元到编程模型,都顺着这条主线流下来。
内存与数据搬运 — 隐式 cache+DMA vs 显式 SMEM+TMA
两边「单机内的分布式」的第二个根本差异 — CPU 让你忘记内存层次,GPU 强迫你直面内存层次。
CPU 的世界里几乎所有内存事都是隐式的:
- 多级 cache(L1/L2/L3)全自动 —
int x = arr[i]时硬件自动决定数据从哪一级取、什么时候换出。 - 硬件预取器(Prefetcher) — CPU 主动猜你下一个访问哪儿,提前从内存取。现代 CPU 同时跑 4-5 种预取器。
- DMA 控制器 — 大块数据搬运(硬盘 / 网卡 / 内存间)由 DMA 处理,CPU 只配置然后该干啥干啥。
- 乱序执行隐藏访存延迟 — load 要等 100 周期,CPU 立刻去执行后面不依赖的指令。
GPU 走完全相反的路:
- 显式分层 —
__shared__/__constant__/ 寄存器 / global memory,程序员要明确选择数据放哪里。 - 显式异步搬运 —
cuda::memcpy_async、TMA descriptor、cp.asyncPTX 指令,数据不会自己从 GMEM 进 SMEM。 - 显式同步 —
__syncthreads()等所有线程,async barrier 等指定字节数。 - 软件 prefetch — 没有硬件预取器,靠双缓冲(double buffering)模式 — 程序员写代码让「算当前 tile 同时,TMA 异步搬下一个 tile」。
把对照排一遍:
| 功能 | CPU 解决方案 | GPU 对应物 | 控制方式 |
|---|---|---|---|
| 缓存最近访问 | 多级 cache 自动 | L1 / L2 + SMEM | CPU 自动,GPU 半手动 |
| 大块数据搬运 | DMA 控制器(外设 ↔ 内存) | TMA(GMEM ↔ SMEM) | 两者都要配置 |
| 预测下次访问 | Hardware Prefetcher | 无 · 靠软件双缓冲 | CPU 硬件 / GPU 软件 |
| 隐藏访存延迟 | 乱序执行 + 推测 | warp 切换 | CPU 单线程挖并行 / GPU 切线程 |
| 内存层次选择 | 透明(cache 自动) | 显式(__shared__ 等) | CPU 隐式 / GPU 显式 |
| 跨设备搬运 | DMA + 系统总线 | NVLink + GPUDirect | 两者类似但 GPU 快得多 |
最有意思的对应是 DMA 与 TMA:概念完全一脉相承 — 把数据搬运卸载给专用电路,让通用计算单元少干这种重复活。差异在于:
- DMA:CPU 外部、跨设备搬运、粒度大(整块文件)、CPU 偶尔启动一次。
- TMA:SM 内部、片上内存层次间搬运、张量结构化(多维)、单线程频繁启动。
为什么 GPU 要把「DMA」做进 SM 内部?因为 Tensor Core 太快,搬数据成了第一瓶颈。把搬运硬件贴在计算单元旁边,才能让搬运指令的开销降到最低。CPU 的 DMA 为「偶尔的大块传输」设计,GPU 的 TMA 为「持续高速喂数据」设计 — 这是同一个想法在不同时间尺度上的两次落地。
哲学差异一句话概括:
CPU 试图让你忘记内存层次(自动管理);GPU 让你直面内存层次(手动优化)。
这就是为什么 CPU 代码「差不多就能跑得不错」,而 GPU 代码「不优化能慢 10-100 倍」 — GPU 把性能调优的责任显式交给了程序员,但作为补偿,它把硬件资源全部交给执行,所以理论峰值高得多。
集合通信六大原语 — Broadcast · Reduce · AllReduce · AllGather · ReduceScatter · AlltoAll
把视角从单机内回到多机分布式 — 集合通信原语是 BSP 通信阶段的具体操作。这一套原语在 MPI 里定义、在 NCCL 里实现 GPU 版、在 Spark 里换名字提供。下面六个图是分布式系统的「原子操作」,任何复杂操作都由它们组合而成:
这张表是最直接的证据 — 每一行都是同一个数学操作在三个世界里的不同接口。Spark 的 shuffle 本质上是 AlltoAll;MapReduce 的 reduce 阶段本质上是 Reduce;PyTorch DDP 的梯度同步本质上是 AllReduce;FSDP 的参数收集是 AllGather + ReduceScatter 的组合。
不同的工程实现关注不同细节 — Spark 关心 shuffle 怎么 spill 到磁盘、怎么 fault-tolerant、怎么 partition;NCCL 关心 AllReduce 用 Ring 还是 Tree、怎么用 NVLink 拓扑、怎么 overlap 计算和通信。但它们解决的是同一类抽象问题。
通信硬件层 — PCIe vs NVLink/NVSwitch · 以太网 vs InfiniBand
集合通信原语跑在通信硬件上,这一层 GPU 和 CPU 世界差异巨大,主要差在带宽与延迟。
| 互联技术 | 单链路带宽 | 延迟 | 拓扑 | 用途 |
|---|---|---|---|---|
| PCIe 5.0 | 64 GB/s | ~1 μs | 共享总线 | CPU ↔ GPU · CPU ↔ NIC |
| NVLink 5(B200) | 1.8 TB/s/GPU | ~1 μs | 点对点 | GPU ↔ GPU 机内 |
| NVSwitch | 全带宽 | ~1 μs | 全互联 | DGX/NVL72 机柜 |
| NVLink-C2C | 900 GB/s | ~ns | 点对点 | Grace ↔ Hopper/Blackwell |
| InfiniBand HDR/NDR | 200-400 Gbps | ~1 μs | Fat-Tree | HPC + AI 跨机 |
| ConnectX-7/8 | 400-800 Gbps | ~1-2 μs | RDMA | NIC,跨机 RDMA |
| Spectrum-X | 800 Gbps | ~2 μs | 增强以太网 | ”AI-优化的以太网” |
| 以太网(普通) | 10-100 Gbps | ~5-50 μs | TCP/IP | 通用数据中心 |
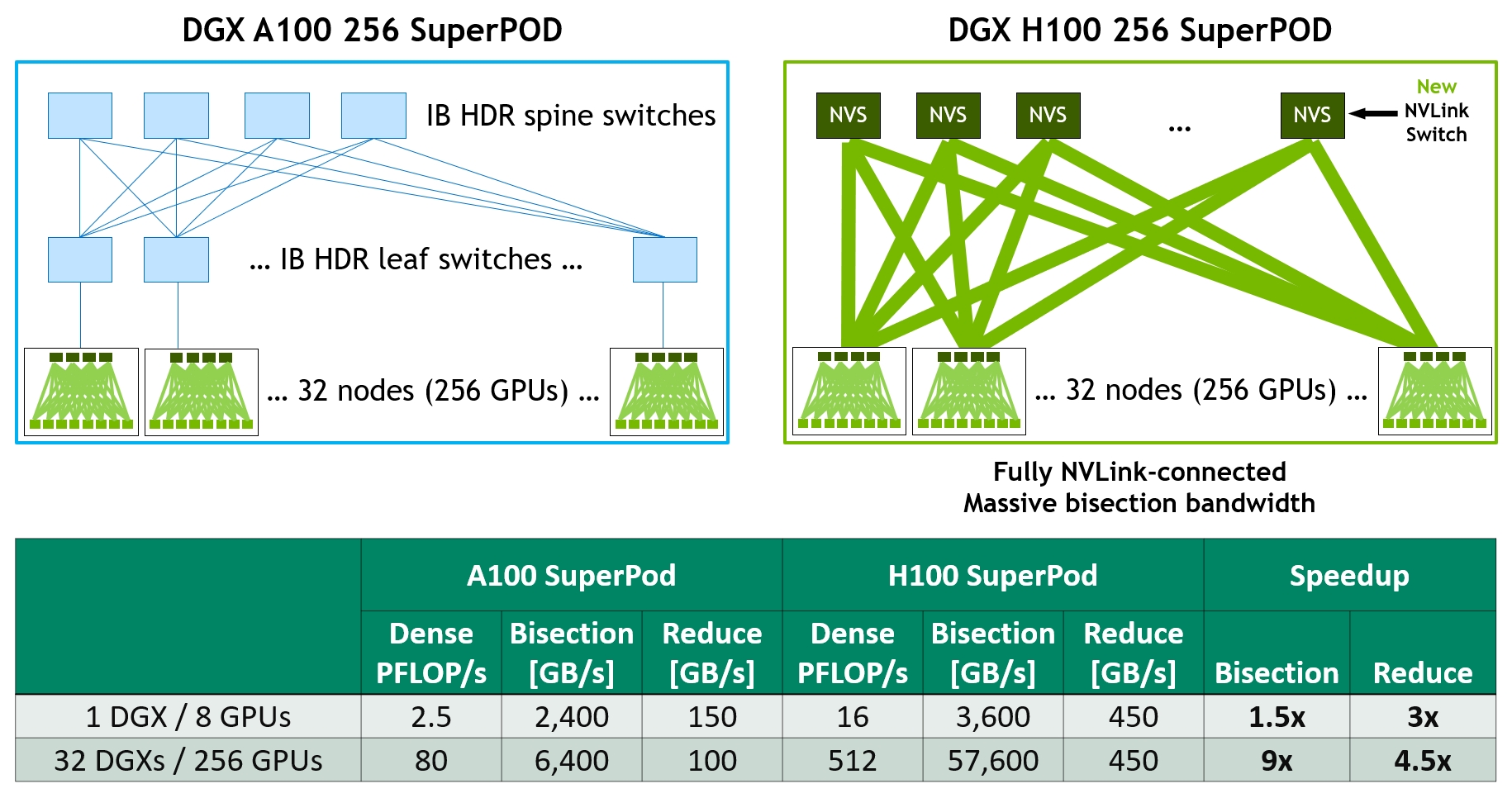
注意:同一个机柜内 GPU 之间(NVLink)的带宽 ~1.8 TB/s,比 PCIe 5.0(64 GB/s)快约 28 倍。这就是「NVLink 域」与「PCIe 域」的本质差异 — 在 NVLink 域内做张量并行(频繁通信)可行,跨 PCIe 做就完全跑不动。
GPUDirect RDMA 这个技术值得专门提一下。传统模式下,GPU 1 把数据发到 GPU 2(在另一台机器)要经过 GPU 1 → CPU 1 内存 → NIC → 网线 → NIC → CPU 2 内存 → GPU 2,要 4 次内存拷贝。GPUDirect RDMA 让网卡直接从 GPU 1 的 HBM 读数据、直接写到 GPU 2 的 HBM,绕过两边的 CPU 内存,变成 GPU 1 → NIC → 网线 → NIC → GPU 2,0 次 CPU 内存拷贝。省下的不只是带宽,还有 CPU 调度开销 — 大规模训练里 CPU 完全成为旁观者。
CPU 分布式世界几乎没有这种「绕过 CPU」的需求 — 因为通信粒度本来就大,几次内存拷贝相对于秒级的 shuffle 时间不重要。GPU 训练里每个 step 几十微秒,任何额外的内存拷贝都会拖累整体,所以才需要 GPUDirect 这种激进技术。
通信软件层 — NCCL · NVSHMEM · MPI · Hadoop RPC
硬件之上是通信软件库。GPU 世界里 NCCL 是事实标准,几乎所有分布式 AI 训练框架都用它做后端;CPU 世界里 MPI 是 HPC 老大,Hadoop / Spark 用自己的 RPC 框架。
| 库 | 粒度 | 同步语义 | 容错 | 谁用 |
|---|---|---|---|---|
| MPI(OpenMPI / MPICH) | 中-粗(KB-MB) | 异步,显式 Wait | 几乎无 | HPC 超算 + 早期 ML |
| NCCL | 中(MB-GB) | 异步 stream | NCCL 2.20+ 才有初步容错 | 所有 GPU 训练框架 |
| NVSHMEM | 细(几字节起) | 单边通信,kernel 内调用 | 无 | MoE 训练 / 自定义高性能 kernel |
| GPUDirect RDMA | 任意 | 异步 | RDMA 网卡自带 | NCCL 自动用 · 工程师不直接接触 |
| Hadoop RPC | 粗(GB-TB) | 同步 + 异步 | 强 · 节点挂自动重算 | Hadoop ecosystem |
| Spark RPC(Netty) | 粗 | 同步 | 强 · RDD lineage 重算 | Spark ecosystem |
| gRPC / Akka | 灵活 | 同步 / 异步 | 看上层用 | 微服务 / 数据平台 |
最值得拆开看的是 NCCL 和 NVSHMEM 的差异:
- NCCL 是「集合通信」粒度 — 一个
ncclAllReduce调用一次同步所有 GPU,适合大块数据。PyTorch DDP / FSDP / Megatron 都用这个粒度。它会自动探测拓扑(NVLink / IB / PCIe),自动选最优传输路径,自动在小消息走 tree、大消息走 ring。 - NVSHMEM 是「单边通信」粒度 — 一个 GPU 直接读写另一个 GPU 内存,不需要对方参与,可以在 CUDA kernel 内部调用。
// NVSHMEM 在 kernel 内部直接发送
__global__ void custom_kernel() {
if (threadIdx.x == 0) {
nvshmem_float_p(remote_ptr, value, target_pe); // 1 个线程发 1 个 float
}
}这种细粒度通信适合 MoE 路由(每个 token 要发到不同专家所在的 GPU)、自定义 attention(GPU 间频繁交换小块 KV)。DeepSeek 的 DeepEP 库用 NVSHMEM 解决 MoE 通信瓶颈,FlashInfer 也大量用。这种粒度在 CPU 世界里完全没有对应物 — CPU 分布式的通信成本太高,根本不可能在「kernel 内部发消息」。
NCCL 给一个 ncclAllReduce 调用做了非常多事:
- 启动时探测拓扑(NVLink / IB / PCIe 互联结构)
- 自动选最优传输路径(机内走 NVLink,跨机走 IB + GPUDirect RDMA,无 IB 走以太网 + TCP)
- 自动选最优算法(Ring AllReduce 带宽优 / Tree AllReduce 延迟优 / Double Binary Tree 折衷)
- 重叠计算和通信(所有 NCCL API 异步,通信在 CUDA stream 上跑)
这一整套自动化让 PyTorch DDP 的 loss.backward() 这一行能在任何机器上跑出接近最优的通信性能 — 程序员不需要懂硬件拓扑。
分布式训练框架四代演化 — Horovod → DDP → FSDP → Megatron-Core
通信库之上是分布式训练框架。过去 7 年这块按「解决什么瓶颈」分成清晰的四代:
第一代(2017-2019)·朴素数据并行
- Horovod(Uber 2017)— 把 Ring AllReduce 从 MPI 搬进深度学习。证明了 PS(parameter server)以外的路可行。已停更(Linux Foundation 接手,但官方维护已停),思想活在 PyTorch DDP 里。
- PyTorch DDP(2018)— 现在的事实标准。
loss.backward()自动 AllReduce 梯度 + overlap 计算通信。 - tf.distribute(TensorFlow 内置)— Google 自家方案,TPU 用户主力。
DDP 的限制 — 每张 GPU 都要装下完整模型。70B 模型不行(参数 + 梯度 + 优化器状态 ~ 130 GB)。
第二代(2019-2021)·内存优化的数据并行
- DeepSpeed ZeRO(Microsoft 2019)— 革命性的「Zero Redundancy Optimizer」。三个阶段:
- ZeRO-1:优化器状态分片(节省 4×)
- ZeRO-2:+ 梯度分片(节省 8×)
- ZeRO-3:+ 参数分片(节省 N×,但通信增加)
- FairScale(Meta 2020)— ZeRO 在 PyTorch 上的实验,已废,所有功能进了 PyTorch FSDP。
- PyTorch FSDP(2022)— ZeRO-3 的官方版本。FSDP2(2024)基于 DTensor 重写,更先进。
ZeRO 的内存优化对照表:
| 阶段 | 分片对象 | 内存节省 | 通信开销 |
|---|---|---|---|
| ZeRO-1 | 优化器状态 | 4× | 与 DDP 相同 |
| ZeRO-2 | + 梯度 | 8× | 略增加 |
| ZeRO-3 | + 参数 | N× | 显著增加(需 AllGather 临时收集) |
| ZeRO-Infinity | + CPU/NVMe offload | 几乎无限 | offload 通信增加 |
第三代(2021-2023)·3D 并行
数据并行 + ZeRO 只能解决「内存够」的问题。当模型大到几百亿参数、训练计算量大到要上千卡,纯数据并行的通信开销爆炸,需要更复杂的并行策略。
- Megatron-LM(NVIDIA 2019)— 第一个真正做对张量并行的库。对 Transformer 做精细切分:MLP 第一个 Linear 列切分、第二个行切分(两次 AllReduce 变一次);Attention 按 head 切分;Embedding vocab 切分。
- DeepSpeed + Megatron(微软 NVIDIA 联合)— 把 Megatron 的 TP 和 DeepSpeed 的 ZeRO 结合,GPT-3 训练框架就是基于这个。
- Colossal-AI(2021)— 国产 3D 并行框架,支持 1D/2D/2.5D/3D 张量并行,学术上更精致。
3D 并行三种维度:
- 数据并行(DP) — 每张卡有完整模型,处理不同数据。通信:梯度 AllReduce。
- 张量并行(TP) — 一个矩阵乘横向切分(8 路 = 切 8 份)。通信:每层 2 次 AllReduce,极频繁。
- 流水线并行(PP) — 模型纵向切分(80 层 → 每 10 层一张卡)。通信:微批 boundary 的 Send/Recv,但有「流水线气泡」问题。
第四代(2023 至今)· LLM 专用 + 异构集成
- Megatron-Core(NVIDIA 2023)— Megatron-LM 的「库化重生」。可组合 API,支持 序列并行(CP)、专家并行(EP),集成 Transformer Engine 自动用 FP8/FP4。
- TorchTitan / FSDP2(Meta 2024)— PyTorch 官方下一代,基于 DTensor 完全重写。
- NeMo(NVIDIA)— 完整 LLM 开发栈,底层用 Megatron-Core。
- Axolotl / LLaMA-Factory / Unsloth — 面向 LLM 微调的高层框架,yaml 配置训练。
把这四代放在一起对照:
| 代际 | 代表框架 | 解决的问题 | 现状 |
|---|---|---|---|
| 第一代 | Horovod / DDP / tf.distribute | 朴素数据并行 | DDP 仍主流(小模型) |
| 第二代 | DeepSpeed ZeRO / FSDP | 模型不止单卡装得下 | FSDP/FSDP2 主流 |
| 第三代 | Megatron-LM / DeepSpeed+Megatron | 万亿参数 3D 并行 | Megatron-Core 接班 |
| 第四代 | Megatron-Core / NeMo / TorchTitan | LLM 专用 + 异构集成 | 当前前沿 |
每一代框架本质上都在更精细地组合 NCCL 的几个原语 — DDP 用 AllReduce,FSDP 用 AllGather + ReduceScatter,Megatron 用全部六种。通信原语没变,组合方式越来越巧。
3D 并行 vs Spark DAG — SPMD vs 数据流
对比两个世界的编程模型,你会发现一个根本差异 — GPU 训练走 SPMD(Single Program Multiple Data),Spark 走数据流(Dataflow)。
SPMD 模型(GPU 训练) — 每个进程跑一模一样的代码,只是处理不同数据。你写:
# 每张 GPU 都跑这段
model = FSDP(model)
for batch in dataloader:
loss = model(batch)
loss.backward() # 自动 NCCL AllReduce / AllGather
optimizer.step()8 张 GPU 上跑的是同一份脚本,启动时通过 LOCAL_RANK 环境变量区分自己是哪个 rank。通信通过 NCCL 原语显式或隐式触发。
数据流模型(Spark) — 你声明数据的变换 DAG,运行时框架决定数据怎么流:
# Driver 上运行
rdd.map(parse) \
.filter(lambda x: x.valid) \
.map(lambda x: (x.key, x.value)) \
.reduceByKey(lambda a, b: a + b) \
.saveAsTextFile("output")你不写「在哪台机器算什么」,Spark 自己分发任务到 worker。Stage 边界(shuffle)就是 BSP 超步的同步点。
3D 并行的五种维度对照 Spark stage 的 shuffle 边界看,你会看到有趣的对应:
| 并行方式 | 通信原语 | 通信频率 | 必须在哪 |
|---|---|---|---|
| 数据并行(DP) | AllReduce 梯度 | 每步 1 次 | 任意 — 通信少,可跨机柜 |
| 张量并行(TP) | AllReduce 激活 | 每 Transformer 层 2 次 | NVLink 域内 — 通信频繁 |
| 流水线并行(PP) | Send/Recv 边界激活 | 微批 boundary | 灵活 — 通信少但有气泡 |
| 专家并行(EP) | AlltoAll(路由) | 每 MoE 层 1 次 | NVLink 域内首选 |
| 序列并行(CP) | 各种 | 取决于实现 | NVLink 域内 |
| Spark Stage | shuffle = AlltoAll | 每 stage 1 次 | 网络可达即可 |
看到对应了吗?TP 因为通信极频繁(每层 2 次 AllReduce)必须放在 NVLink 域内(机柜内 GPU);DP 通信少可跨机柜;Spark 的 stage shuffle 在数据级别也是 AlltoAll,只是 Spark 在分钟级,GPU 训练在微秒级。
这种「通信成本决定布局」是分布式系统的普遍模式 — 不只是 GPU 训练,Spark 集群规划、数据库 sharding、CDN 节点选址,本质都是「通信频繁的近放、通信稀疏的远放」。
关键工程差异大对照 — 容错 · 粒度 · 频率 · 编程模型 · 拓扑感知
把所有差异汇总到一张表里 — 这是这篇文章的核心总结:
| 维度 | GPU 分布式(NCCL + DDP/Megatron) | 传统分布式(Spark / MapReduce) |
|---|---|---|
| 通信延迟 | 微秒级(NVLink ~1 μs) | 毫秒到秒级(网络 + 磁盘) |
| 通信带宽 | TB/s(NVLink) | GB/s(网络) |
| 节点规模 | 几张到几千张 GPU | 几台到几万台机器 |
| 故障假设 | 几乎不容错 — 一挂全卡死 | 必须容错 — 节点经常挂 |
| 数据局部性 | 数据在 GPU 显存里 | 数据在 HDFS / S3 上 |
| 计算密度 | 极高(Tensor Core 万次 FMA/cycle) | 中低(CPU 简单运算) |
| 同步频率 | 每个 step(毫秒级) | 每个 stage(分钟级) |
| 核心瓶颈 | 通信带宽 + 内存带宽 | 磁盘 I/O + 网络 + 内存 |
| 容错策略 | Checkpoint + 重启 | RDD lineage 自动重算丢失分区 |
| 编程模型 | SPMD(每 GPU 跑相同代码) | 数据流 DAG |
| 任务粒度 | 一次 step 即一个 superstep | 一次 stage 即一个 superstep |
| 通信原语 | 集合(AllReduce / AllGather / AlltoAll) | shuffle / broadcast variable |
| 同步语义 | 异步 NCCL + barrier | Stage 边界 |
| 拓扑感知 | 极重要(NCCL 自动探测) | 不重要(网络足够好) |
最值得品味的几行差异展开讲:
容错的不同来源差异 — Spark 必须容错,因为它运行在「上万台便宜机器」上,每天都会有几台挂掉。Spark 的核心思想 RDD(Resilient Distributed Dataset) 就是「如果数据丢了,根据 lineage 重算」。GPU 训练几乎不容错 — 千卡训练里如果一张 GPU 挂了,整个训练卡死(NCCL 默认 30 分钟超时)。
为什么 GPU 训练不容错?三个原因:
- GPU 之间状态高度耦合(每个 step 互相依赖,不像 Spark task 独立)
- 「重算」成本远高于 Spark — Spark 重算一个 task 是几分钟,GPU 重算一个 step 要重新加载整套参数
- BSP 的 barrier 让任何节点的延迟都拖累全局 — Spark 容忍掉 1% 节点慢,GPU 不能
实际处理方式:训练框架(Megatron / NeMo)定期 checkpoint,故障后从最近 checkpoint 恢复。Anthropic / OpenAI 这类公司都有专门的运维团队处理故障。
通信粒度差异决定了 GPU 训练的所有优化 — Spark 一次 shuffle 可能搬几 GB,毫秒到秒级;NCCL 一次 AllReduce 可能搬几 MB,几十微秒。但 NCCL 频率高几个数量级 — 一次训练 step 就可能调几十次 AllReduce。所以「重叠计算和通信」在 GPU 训练里是性能命门,在 Spark 里几乎不重要。
编程模型差异是表象不是本质 — 看起来 Spark 像「数据流」、GPU 训练像「SPMD」是两种完全不同的编程模型。但本质上 Spark 内部最终也是 SPMD — 它只是把 SPMD 包装成「数据流」的抽象,让用户更好写。所以这个差异在最深层是不存在的。
统一理论框架 — Amdahl · BSP · 集合通信原语
把所有差异归零看,统一理论框架由三个锚点构成:
锚点一:BSP 模型 — 1990 年 Valiant 提出的并行计算理论模型。任何 BSP 计算分成连续超步,每超步含三阶段:本地计算 → 通信 → 全局同步(barrier)。我们前面已经看到 — PyTorch DDP step、Spark stage、MPI program、MapReduce job 都是 BSP。
锚点二:Amdahl 定律 — 1967 年定的「并行计算基本物理定律」:
其中 是串行部分占比, 是处理器数。告诉你即使有无穷多 GPU,串行部分也会成为瓶颈。如果 5% 代码必须串行(初始化、汇总),那 1000 个 GPU 最多也只能加速 20 倍。
这就是为什么「流水线气泡」、「通信开销」、「梯度同步等待」是分布式训练的核心问题 — 它们都是 Amdahl 定律的串行部分,会按比例吃掉总加速比。
锚点三:集合通信原语 — MPI 标准化的六个通信模式(Broadcast / Reduce / AllReduce / AllGather / ReduceScatter / AlltoAll),覆盖了 BSP 通信阶段的所有典型操作。NCCL 是 GPU 版,Spark 把它包装成「shuffle / broadcast variable / reduce」。
这三个锚点合起来,足以描述从 1990 年到今天的所有大规模并行/分布式系统。MPI 程序、Hadoop MapReduce job、Spark application、Horovod 训练、PyTorch DDP 训练、Megatron 3D 并行训练 — 都在这个框架里。
这就是为什么术语会重叠 — 理论统一,所以语言统一。差异在于工程实现 — 不同约束(同构 vs 异构、可靠 vs 不可靠、紧耦合 vs 松耦合、计算密集 vs 数据密集)催生出不同的实现方案,但描述它们的语言是同一种。
「理论统一、工程发散」这个模式在计算机科学里非常普遍 — 操作系统(进程调度的统一理论 → Linux/Windows 不同实现)、数据库(关系代数统一 → SQL 实现千差万别)、网络栈(OSI 七层统一 → 各种协议)、编译器(编译原理统一 → LLVM/GCC/MSVC 各有特色) — 都是同样的格局。理解这一点能让你跨领域迁移知识 — 学过 Spark 的人理解 NCCL 比从零开始快 10 倍,因为 BSP 的认知框架已经建立。
总结 — 当 reduce 三个字在两个世界里说同一件事
回到开头的疑惑 — Spark reduceByKey 和 NCCL AllReduce 名字一样、做的事一样、毫秒到微秒差 1000 倍 — 这怎么可能? 答案是简单的:
它们就是同一回事 — 同一套数学(BSP + 集合通信),只是约束条件不同所以工程实现差出几个数量级。
把这篇文章浓缩成几个判断:
- 所有大规模并行 / 分布式计算系统在数学和算法层面是统一的:BSP 三段式超步 + Amdahl 定律 + 集合通信原语,30 年没变。
- 区别完全来自工程约束:同构 vs 异构硬件、可靠 vs 不可靠节点、毫秒 vs 分钟级通信、紧耦合 vs 松耦合状态。
- GPU 分布式和 CPU 分布式同源:都流自 1994 年的 MPI 标准、1990 年的 BSP 模型。术语重叠不是巧合。
- 关键差异在通信粒度:GPU 训练微秒级 step + 频繁通信,所以「重叠计算和通信」是性能命门;CPU 分布式分钟级 stage + 稀疏通信,所以「容错与可扩展性」是核心。
- 未来 5 年的演进方向:GPU 分布式会继续把更多 CPU 分布式的特性吸收过来(容错、弹性、推理调度),而 CPU 分布式不会反过来吸收 GPU 的紧耦合 — 因为后者本质上是放弃容错换性能。
你下次看到任何分布式系统的新框架 — Ray、Dask、FlyteX、新的 ML 推理调度器 — 都可以先问三个问题:
- 它的 BSP 超步多大?(毫秒还是秒还是分钟)
- 它怎么处理失败?(节点挂了发生什么)
- 它的通信原语映射到哪几个 MPI 原语?
把这三个问题答清楚,你就把它在分布式计算的版图里精确定位了。
参考资料 — 论文 · 教科书 · 课程
论文
- Valiant (1990) “A Bridging Model for Parallel Computation” — BSP 模型的原始论文。短小精悍,40 分钟可以读完,但是这个领域最重要的论文之一。
- Dean & Ghemawat (2004) “MapReduce: Simplified Data Processing on Large Clusters” — Google MapReduce 论文。13 页,把「容错的并行计算」讲清楚的开山之作。
- Zaharia et al. (2012) “Resilient Distributed Datasets” — Spark RDD 论文。14 页,讲清楚 lineage 容错的核心思想。
- Patarasuk & Yuan (2009) “Bandwidth Optimal All-reduce Algorithms for Clusters of Workstations” — Ring AllReduce 原始论文。NCCL 的核心算法基础。
- Sergeev & Del Balso (2018) “Horovod: fast and easy distributed deep learning in TensorFlow” — Horovod 论文。讲述 MPI 思想搬进深度学习的历史时刻。
- Lamport (1978) “Time, Clocks, and the Ordering of Events” — 分布式系统理论开山之作。讲分布式时钟、因果序、Lamport timestamp。
教科书
- 《Introduction to Parallel Computing》 by Grama, Karypis, Kumar, Gupta(2003) — 并行计算标准教材。BSP、集合通信、性能模型都讲得很清楚。
- 《Designing Data-Intensive Applications》 by Martin Kleppmann(2017) — 数据系统圣经。讲分布式系统的一致性、容错、流式处理,对理解 Spark / Kafka 等极有帮助。
- 《Distributed Systems》 by Tanenbaum & Van Steen(2017) — 分布式系统经典教材,更偏 OS / 系统视角。
课程与文档
- MIT 6.824 Distributed Systems(Robert Morris) — 所有讲义和论文都公开,系统讲分布式系统经典论文。pdos.csail.mit.edu/6.824
- CMU 15-418/15-618 Parallel Computer Architecture and Programming — 并行计算入门,讲 SIMT / SIMD / Cache coherence 等机器层概念。
- NVIDIA NCCL 文档 — Ring AllReduce 算法选择、拓扑探测等工程细节。docs.nvidia.com/deeplearning/nccl
- PyTorch Distributed 设计文档 — DDP/FSDP/FSDP2 的内部实现,值得读。